


 1
1 0
0 1
1


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






不管那些云计算服务提供商怎么宣称自己服务的可用性,他们保证得越好,出现故障时的影响也就越显著,尤其是像亚马逊AWS这种元老级别的云计算服务。大约在北京时间本周三凌晨,就当亚马逊负责云计算业务的副总裁在台上宣讲AWS的优势时,AWS突发故障,导致运行在其上的大量网站访问受到影响。

出现故障的节点在AWS美东1区,共计33个服务受到影响,其中9个处于完全中断状态,包括上线时间最长的,亚马逊首个云服务产品,存储服务S3(Simple Storage Service)。久经考验的S3颇受业界信任,许多网站都把它当作自己的后端存储,像github、Dropbox、Quora、Netflix、ESPN、AOL等等大型网站都在S3上储存自己的数字资产。由于S3本身就是一个跨地域分布存储服务,可用性极高,十多年来也没有出过这样的大问题,所有人都没有预料到它也会有故障下线的一天,结果都被打了个措手不及。
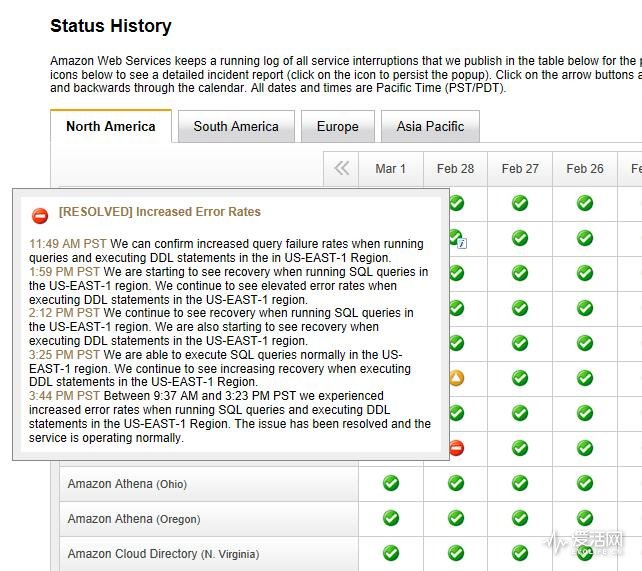
虽然亚马逊官方口径表示这次故障只是导致了AWS服务“报告的错误率上升”,拒绝承认AWS发生“服务中断”的情况,但大家的实际体验里是基于美东1区的那些站点下线时间长达4个多小时。百度或许应该感谢一下亚马逊替它吸引火力,因为刚好也是在当晚,百度的移动端也出现了无法访问的情况。
在事后调查结束之后,亚马逊今天还原了周三事故的过程:
不论如何,云服务商的虚拟机和存储如何再作迁移备份和可用性保障这一问题,又一次被放到了各位IT技术的桌面上。
要发表评论,您必须先登录。



这哥们也要看一千遍 nyan cat?