


 2
2 0
0 2
2

从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






近日,Smile Vector在推特上更新了他们的机器人程序,AI已经掌握了随意改变照片表情的新技能。这个技术可以从网络上的扒下任何人脸图片,然后经过深度学习神经网络,生成微笑的表情。

不同于一键美白的app,尽管机器人目前的微笑还有一些尴尬,但是整个脸部表情的捕捉、生成都是自动。
假新闻几乎要成为2016的结语词,人们责怪社交平台、贪婪的所有人都遍故事的马其顿小镇、愚蠢只知道看图说话的传播者。而当伪造图片、视频技术完全人工智能化,人类不再需要任何技术,当PS变得和word一样简单,那么图片、影片的伪造,就会变得像文字一样任人蹂躏。眼睛,将成为最不可信的部分。
怪事年年有,今年特别多,有人说,这都是技术惹的祸。
Smile Vector并不是人工智能在多媒体领域唯一,或者最成功的产品,事实上,像这样通过AI的学习,掌握修改图像、影片的能力的技术开发,已经变得越来越成熟,对用户来说,通过AI的产品修改图片和视频,将变得前所未有的容易。
除了修改图像,人工智能在制图、绘画能力已经有了显著的提升。怀俄明大学的副教授Jeff Clune有一个通过数据库来训练神经网络,训练AI绘图的项目。他们从2005年Quian Quiroga的“当人类面对某些特定的画面时,人类的神经系统会获得一些刺激”的研究中获得了启发,并开始调教AI。
在2015年的时候,人工智能还只能模糊地描绘出一部分特征,到了2016年,他们已经能够准确地抓住内涵,当他们有了足够多的学习后,就能够根据指令,生成清晰的图片。


在开发者看来,人工智能图像生成,将为创意产业提供全新的帮助,AI将通过自己的绘画,为人类带了新的想法,指引新的方向。以家具设计师来说,当AI学习到了足够多的数据之后,它自动生成的桌子、椅子,一方面是有现实依据的,另一方面,也可能碰撞出人脑没有想象到的火花。

当然,直接生成图像的项目也有自己的瓶颈,由于缺少更高分辨率的数据库,目前能够生成的图片都在256*256的大小。科学家么你还没有生成真实的、高清图像的时间表。
不过,一旦这些技术被完善,那么投入商用的他们,很有可能会失去严肃的本质,成为全民娱乐中的一员。

人们已经可以想象到,从2D画面生成3D脸部模型的技术、实时改变视频面部表情、自动生成声音等AI多媒体技术将会成为了许多人自娱自乐的工具。比如,今年3月发布的Face2Face,它逼真地将一个人的面部表情、肌肉运动,完美地、实时地复制到正在播放的视频中的另一个人身上。
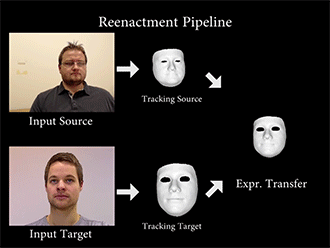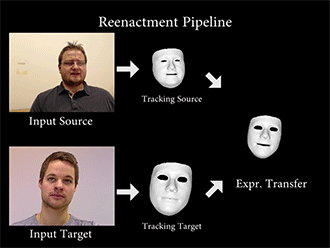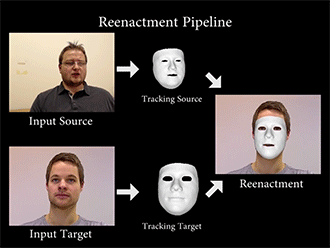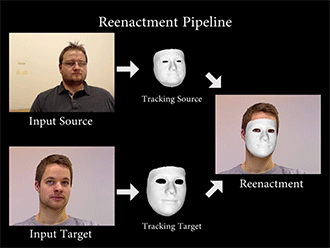
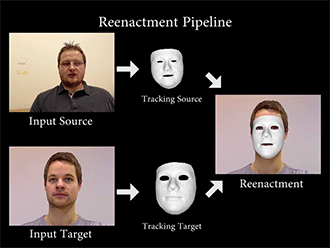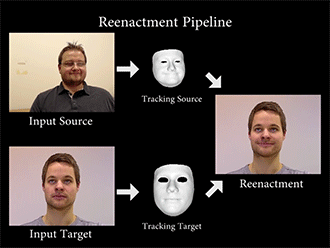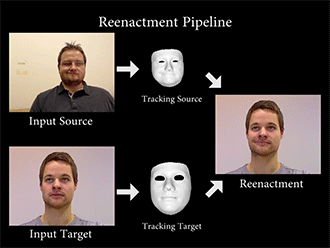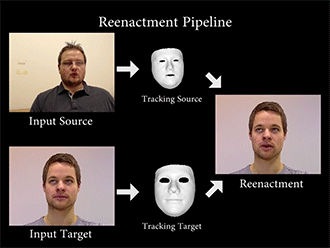
Face2Face通过特定的算法,重构源图像(source)和目标图像(Target)的面部特征,然后将一种变形函数套用在模型上,再次渲染目标图像的面部形状、阴影、光照等,最后将模型与背景复合,最终维持目标图像的嘴部形状,造成以假乱真的效果。
眼看着一项项的技术被发表,眼见为实的古训成为笑话,越是拥抱技术,就有人越警惕技术。其实,在小编看来,和所有的影视作品、小说文本一样,技术所产生的效果,是由创作者、技术本身和应用者三方共同作用而成的。正如导演与影评人之间永远对作品有不同的想法一样,在技术的三角关系中,当一项技术来到了使用者的手中,它能够发挥的效果,往往是开发者想象不到的。
就算是Facebook被传统媒体因为假新闻问题喷得体无完肤,“假新闻”的出现,作为平台的Facebook并不是始作俑者。早在1860年,人类就将林肯的头安在了卡尔霍恩的身上,伪造了历史上的第一幅假照片。彼时,距离世界上第一张照片的出现,也不过30多年的时间。

不论是照片还是文字,纪录片还是新闻报道,即使在它的基本定义中,事实是这一切的基石,每个人都不可避免地对另一个对象产生偏见,再通过技术传播出带有主观意识的讯息。佛拉哈迪的纪录片《北方的纳努克》,是世界上第一部长篇记录电影,它刻意抹掉因纽特人用现代猎枪打猎的摆拍场景,引发了广泛的争议。然而今天的纪录片中,我们还是常常能够看到用动物园的幼崽冒充野生纪录片的“惯用手法”,不论是在学生习作,还是专业的BBC拍摄的纪录片中。

即使没有PS人类还是会“剪辑”,即使没有AI造图,还是有全村的人一起写假新闻赚钱。所谓的技术打破了“专业人员”的壁垒,让“造假”变得更加容易,就更加是个伪命题,谁都有权利用新的技术向世界宣告自己的偏见,作为每一个有独立意志的人,从中获得新的启发、辨别优劣本来就是存世的本领之一。而当技术越发成熟,越发开放,每个人都会获得更好的攻击或者防御能力。
技术,永远是最中性的,而使用者的底线、目的才是人类最需要去规范的。当然,用旧有的技术的手段去管理新技术,可能产生一定的时间差,也更加考验人类的学习能力。
要发表评论,您必须先登录。



were so proud of you.
封面图是SQL代码,图文不符啊