


 0
0 0
0 0
0

从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






微软小冰到今天已经迭代了7个大版本,今年推出的第七代微软小冰已经开始有“为人而定制”的倾向,而且拥有越来越强的创造能力、绘画唱歌愈发熟练,情感引擎的不断进化让AI变得“越来越像人类”。这些进步必然使得我们也会开始猜想下一个阶段,微软小冰还要如何在哪些方面提升自己?是什么在背后推动这种进化?

最早的人工智能在对话处理上是生硬的一问一答,命令/答复式交互;但随着对话引擎的不断迭代,自然语言处理模型的改进,微软小冰在数代的发展过程里逐渐培养出了多轮对话的能力。

针对这个能力,微软认为其中一个重要的特质是“自我完备”,从字面意思上解读的话,就是AI需要有自己补充单纯在对话语句文本里所缺少信息的能力。人类对话的沟通不光是文字层面,在文字之外,感情、场景,上下文的画面感等等,想象力和常识可以帮我们在阅读到这些文字的时候补完这些内容,但AI面对这种场合,就需要具备这样的“想象力”——也就是这里微软所说的“自我完备”。

为了让小冰在多轮对话中具有类似于人类的脑补判断能力,微软提出了几个关键性的技术思路:
第一个是学习,这里面包括低层次的让AI学习人类说话的基本思路,还有学习其他机器人说话的拓展手段。学习人类说话是一个从检索单句答案、到匹配语料库生成段落语义回答,最后进化到无监督自行补全上下文,与人类共感的过程;而学习其他对话机器人可以通过信息分享和能力互补,让对话模型能相互教授,相互学习,共同进化。
第二个是对话自我管理,即控制对话流的节奏,而不是一直被动地等待人类端的输入,更加主动地推动沟通往AI的对话预期导向。前述所获得的共感模型已经能够帮助小冰推定“说什么”,并从对话上下文来决定“如何说”;在这其中,小冰还会借用强化学习,使用最大相似度估计,分析上下文语句关键字等手段,帮助自己理解和掌握对话主题。
第三个是多模态知识的连接——在人类之间的对话里,经常会出现主题的关联和跨越,对话机器人在一般情况下,很难就对话主题发散开来,不会“触类旁通”;在具备多模态知识连接的条件下,就相当于赋予了机器人“常识”,更能让话题通过不同主题的跳转过渡,维持对话继续下去。

小冰的这些特点,微软已经在之前分享过的零售场景应用,还有日本线下水族馆的“一日约会”活动中有所展现。微软还额外举了一个很有意思的例子,就是前面体到的无监督自训练话题模型效果对比,相比只能给出简单回复,没有什么内容的基于注意力机制的序列到序列模型,微软的模型能够从“我的皮肤很干”的对话上文里,推出“那你就补水保湿吧”的回复,比嗯嗯啊啊我也是一类的无意义回复更容易保留人类继续对话的欲望。

微软小冰为什么会选择唱歌,恐怕是一个非常令人在意的问题。一般来讲熟悉二次元的人会很自然联想到虚拟歌姬,然后又到现在的虚拟主播……不过微软的想法倒是很单纯,在2015年为小冰增加语音聊天支持之后,一路强化语音能力下来最后开始学唱,看似是为了补完人设,实际上工程师们只是觉得唱歌的挑战性比普通的语音用例强而已。

那唱歌的挑战性究竟体现在哪?微软认为在三个方面,第一是唱歌比说话门槛高,一般人都会说话,但不是所有人都能唱好歌,这里面有技术的难点;第二是唱歌在情感表达上更加丰富激烈,这与微软小冰所塑造的情感引擎不谋而合;最后,唱歌本身是一个很有市场前途的娱乐形式,在音乐选秀类节目大行其道的今天,比较容易找到直接应用的方向,但大众是否接受虚拟歌手是个问题。
有关于技术门槛,AI唱歌的技术难点其实也就是存在于歌咏技巧的三个基本元素里——首先是唱歌的吐字发音一定要清晰,虽然也有哼哼就好唱出来的歌,但要做到“有周姓知名歌手内味”没那么简单,所以字正腔圆还是基本要求;然后是节拍和旋律,控制节拍来表达艺术意图,比较显著的例子是说唱;而旋律则是音高的流动组成的,音高不对演唱就会跑调,旋律正确在所有歌曲里也是基本要求。
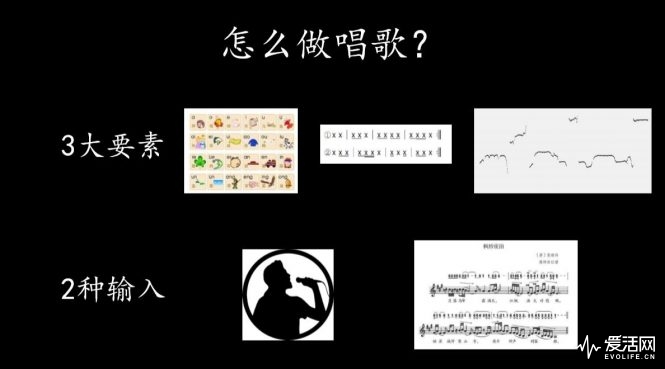
既然要求那么高,小冰要怎么学?一般来说机器人学习唱歌就两个途径,一个是人声原唱声音波形输入,另一个是数字曲谱和歌词输入。前者是一种比较直接、简单和广泛的学习方式,对人类来说模仿比解读要简单;而后者则对机器来说比较友好,因为没有解析波形这个从模拟到数字的过程里,容易产生的音高和节奏误差。
导入了数据之后,剩下的部分就是演绎。对AI来讲,演绎就是一个把输入转化成波形表现出来的合成过程。传统的唱歌合成方式用的是单元拼接,通过采集单音音节发声作为单元库,然后与曲谱匹配选择。这种手段简便易行,音质易保留最高音质;问题是拼接结果容易变得生硬,过渡和变化效果都不好。

而现在大家用得比较多得是隐马尔可夫模型参数合成,不需要建立单元库,直接从所有录音提取出声谱参数、节奏序列和音高轨迹,然后用声码器重构波形,自然且流畅度高,灵活多变可塑性强,缺点是经过了模拟到数字,再回到模拟的过程,音质会不如单元拼接。尽管如此,小冰还是选择了参数合成的方法,从本身就是数字化形象的角度来讲,保真并不是那么重要,不如保留数字化的创造性优势。

确立了方向之后,小冰就开始了模型迭代和优化,挖掘更多歌唱数据,最后在现在这版最新的模型里,微软已经用上了卷积神经网络,专注力和残差连接等结构,可以对发音、节拍和旋律进行同时建模,演唱的准确率、自然度和流畅度都已经达到了不错的水平,以至于在最新版小冰里,它已经可以用特定的唱腔来演绎歌曲,别有一番风味。
在人类的语言能力里,修辞是强化表达的重要手法,而如果要讲深入、更具衔接性的上下文创作,而不只是写几句松散的诗句,那学习修辞技巧必然是绕不开的。

在修辞手法里,最基本的就是比喻/暗喻,在AI的对话和文字创作里用上这个手法,能够让人类感到对话更具吸引力。可是要如何让AI理解这种修辞手法何时用,如何用,怎样用好,就是个值得研究的课题。而且微软还要求小冰不能从人类已有的文章里直接照抄比喻句,不适用“像……一样”一类的匹配模式挖掘数据然后填空,而是真的创造人类未曾用过的比喻。
一句比喻句需要一个本体、一个喻体,以及将本体与喻体连接起来的解释。通常来说,本体比较抽象且不易理解,喻体则是人们大多能在生活中找到实体的事物。处理这些对AI来说比较容易,可以通过收集和排序来区分使用热度,来判断哪些是最频繁成为本体的概念,哪些又是好的喻体。

但难的是如何解释比喻关系,比喻的两端往往摆着两个毫不相关的东西,如果没有一个恰当的解释,且不论比喻新颖与否,句子不够通顺,比喻不太恰当,无法自圆其说,那人一眼就能看出来。
微软的办法是词语嵌套,通过降维词语到二维向量空间上,然后比对与本体与喻体相关词语的关联程度,算法最后所选择的词语会较大概率处于二者之间的平衡带,结果会带有一种非常微妙的契合感:比如“爱情就像葡萄酒,对程序员来说都是奢侈品”这种喻句……

也许你会觉得这样一个复合句会充满机器的气息,所以微软也尝试了在表达上使用一些更具互动性的手法,通过在和人类的交互过程里,把比喻句拆为两轮,做成设问诱导人类好奇,再自答的过程,这种设问式的比喻句会比单纯的陈述句更吸引人。

比喻在某种程度上体现了人类的联想能力,而微软也希望小冰能像人类一样,能够天马行空地想象——在这里,工程师们引入了跨模态理解的概念。简单来讲,就是文字和图片的关联,文字和场景的关联构建之类,让文字和感官挂钩起来,赋予AI“五感”和文字描述内容的联动能力。
微软以一个北极熊猎杀海豹小段落作为例子来说明,人类在阅读这类文本时,我们脑海里就会自然构建这种画面,而在这个过程中,大脑也会调动对应的感官来强化这种画面感。也就是立足于文本之上脑补视觉听觉嗅觉味觉触觉。而且人能够充分运用“常识”,在语言的描述之外,分析出暗含的信息——例如北极熊悄然接近猎物,有时会用爪子靠近自己的鼻子。人类能推断出这是因为北极熊的毛发是白色而鼻子是黑色,这样隐蔽性更高更不容易被猎物发现,而机器却很难做到这种程度的理解。

正是因为如此,近三十年来,AI所热衷于的课题都是围绕着连接主义,而非符号主义。现在的热门课题,文本到图片转换、文本到视频转换,故事可视化,其实就是在AI对语言理解和分析的基础上,用另一种模态来重构文本的内容。
而在这之间,要把AI根据文本故事所生成的“想象”绘本呈现在人眼面前,得到能和人类记忆联想相同的效果并不是一件易事。微软已经在图文密集匹配和双向一对多匹配上下了很大功夫,不过在故事上下文一致性上还有提升空间,因为图片里的故事主人公一直都在变换。

不过这也是促使小冰一直向前进化的动力,每一年她都在扩展自己的技能树,不断提高进步的门槛。今年她可能会以开始探索跨模态理解为2019的小冰版本画上句号,但这不是结束,微软的目标是让小冰可以像人一样理解事物,并基于自己的理解上和人类进行交互,这样才能构建出独立的AI beings概念形象,并以此成为所有虚拟人工智能人格的基石。



