


 2
2 0
0 2
2


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






OpenAI打刀二,DeepMind玩星际,我们迟早有一天会碰到不同分支的强化学习AI上演电竞角逐的好戏——什么你说已经有了?好像《DOOM》的AI大战确实发生过……先不讲这么远,今天凌晨DeepMind公开直播了五场它的AlphaStar AI与人类职业选手的表演赛,虽然MaNa在最后一盘比赛中胜出,但也只是挽回些许颜面:加上此前的没有直播的比赛,AlphaStar的头十场对局里未尝败绩。

关于选择星际2,以及它对于AI研究的意义此前已经说过好几次,主要是因为相比围棋,星际因为有战争迷雾的存在,本身是不完全信息博弈,AI只能根据它所控制的地图部分和侦察所获得的信息来猜测对手的战术战略意图,并制定自己的对策和操作执行。
DeepMind为这次对决通过内部竞争养蛊的方式养出了三套能够和人类一决高下的AlphaStar分支,分别为“普通型”“操作超越人类极限型”和“拟人化型”,从字面意思也能猜到三个分支的个性,同时,DeepMind还限制了AlphaStar的反应速度到300ms,APM最高也设定在了280,整体思路就是让它的反应能力在接近人类极限的位置上,然后让它不纯粹以来机械计算的速度优势来击败人类。
不过实际上AlphaStar在对局里面还是有一些人类选手几乎不可能做到的微操从而逆转,让MaNa惊叹“我当时都以为我已经赢了”。而且目前AlphaStar只能在一张地图上打流程相对固定的PvP对局,其他更为复杂的种族掌握和针对不同地图的变通能力还是欠缺的。但根据对AlphaStar决策过程的观察,它通过自己“屏幕”内容的分析和观测,判断当前局势,下达运营或战斗指令都已经很像人类玩家的作风。
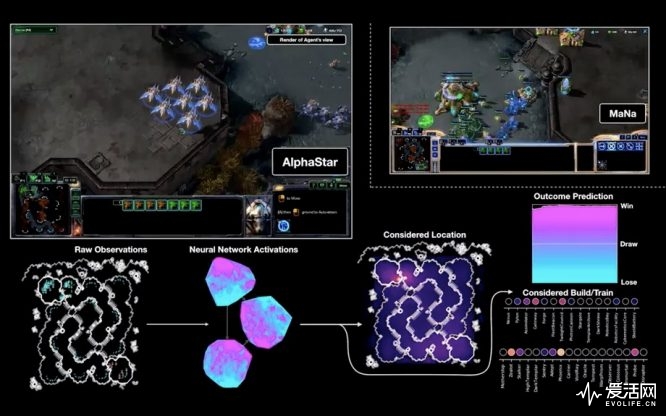
DeepMind不会满足于此,它希望借助这种不断的尝试,让AI能从不同的结果中学习和自我提升,并最终找到和人类一样的自我学习算法——如果这一点得以实现,那真正和人类思想一样的AI就指日可待了。
要发表评论,您必须先登录。



搞搞清楚,前面十场是电脑开全地图不限制微操的,只有最后一场是和人类相同条件,就输了。deepmind最后会赢的,但不是这次
问一下有打麻将的ai吗?