


 9
9 6
6 9
9


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






地球上有没有一种安全漏洞,广泛存在于各种计算设备之中,并且难以被检测,难以被修复?在2018年的第一个月里,Meltdown 与 Spectre 两大处理器安全漏洞给出了这个问题的部分答案。
信息安全行业有一类很高端的攻击方法,叫做边信道攻击(side channel,也有译作侧信道攻击,或旁路攻击的),听着就感觉很高级有没有。这种攻击出现于上世纪 90 年代,以色列的高等学府似乎经常研制边信道攻击的奇技淫巧——所谓的边信道,就是不从正面进攻,而是从侧面窃取或传递信息的方式,比如利用设备运行时产生的电磁辐射,或者电流导致的机械波动噪声,来分析破解出密钥,甚至还能利用散热风扇产生的噪声、机箱上的 LED 灯闪烁变化来将信息传出。
许多边信道攻击条件都非常苛刻,而且攻击噪声比较大,情报获取的正确率有时很堪忧,所以边信道攻击在此之前只有 2016 年精妙的 Linux TCP 漏洞(CVE-2016-5696)造成广泛的影响[1]。
如果将各种漏洞比作攻击武器,那 Linux TCP 漏洞之前的各种边信道攻击类似冷兵器——致命但难以造成广泛破坏。Linux TCP 漏洞攻击思路则将边信道攻击水平提升到了热兵器时代,1 年之后,Meltdown 和 Spectre 漏洞正式开启了热核时代(即便边信道攻击本身严格意义上并不需要漏洞的介入)。

核武 Meltdown(熔断)和 Spectre(幽灵)尽管只有两个名字,但却包含了 3 个漏洞分别是 CVE-2017-5753/5715/5754 [2])。理论上将影响一切现代处理器,借助这三个漏洞,黑客能窃取信息,比如你的密码、个人敏感数据,甚至拿下整个内核地址空间;运行个极为隐蔽的恶意程序,或者点个网址链接,就能让你的信息泄露。由于漏洞存在于硬件层面,因此杀毒软件和个人防火墙很难对攻击进行检测,遑论防护。
截至 2018 年 1 月 10 日,包括 Intel、高通、Apple、NVIDIA、ARM 均承认旗下处理器受 Meltdown 和 Spectre 两个漏洞影响。Intel 受伤最深,从 25 年前 Pentium 75MHz 开始全部中招,就连体系架构完全不同的 Itanium、Xeon Phi 都无法幸免。高通和 ARM 则确认所有带有 OoO(不是表情符号,Out of Order 乱序执行)的 ARM 架构都受到影响。相比之下,NVIDIA 则幸运得多,旗下的 GPU 只受到 Spectre 漏洞影响,而对 Meltdown 免疫。至于 AMD 处理器和其他处理器指令集结构(ISA)如 MIPS64、ALPHA 等,我们认为其有可能对 Meltdown 免疫,但大概率存在 Spectre 漏洞——大量企业级、电信级路由器防火墙都使用 Cavium 基于 MIPS64 ISA 的 SoC,不少超算包括太湖之光都使用了 ALPHA ISA。
早在 2013 年,就有人根据 Intel 处理器的三级缓存架构提出了专门的缓存攻击思路,并将此攻击思路命名为 FLUSH+RELOAD。这种思路利用了现代处理器线程之间共享缓存的设计,通过冲刷和重载来实现目标线程的劫持和攻击。简单地说,现代处理器内执行的 N 个线程就相当于一幢楼中每个使用自来水的家庭,缓存就像大家共用一个自来水水箱。如果其中一个家庭在水箱中投毒,将会导致所有家庭都中毒。现代处理器的 Cache 本质上是 SRAM,也需要持续的冲刷,这给此类攻击制造了大量机会。

这次有关 Meltdown 攻击和 Spectre 攻击,美国几家学府和安全公司的研究人员共同发布了两篇技术 paper,这两篇论文均提到了上述 FLUSH + RELOAD 的攻击方案 [3]。
当代操作系统有个特性叫 page sharing,就是不同的进程可以进行主内存的共享。Page sharing 的价值主要在于两个联合运行的进程通讯更方便,还能减少内存占用。本质上这是一种内存复用的思路,这种基于内容的 page sharing 用于在进程执行和使用共享库时,可执行文件正文段的共享。而且不止是操作系统,如今的主流虚拟化 Hypervisor 其实也用这套方案。比如云计算技术中普遍采用的 de-duplication,就是不同虚拟主机共享一个内存模块的技术,也是同理——像 VMware ESX、PowerVM 之类的 hypervisor 都是支持的。
系统对于共享 page 的映射,采用 copy-on-write(COW) 的方案——就是对改动的数据延后写入到内存中,这也是 FLUSH+RELOAD 攻击可导致信息泄露的一个基础。
两个进程共享内存页,到了线程层面也有很大概率共享处理器上的缓存 Cache 部分。Cache 是连接主内存和处理器前端的缓冲地带,其读写速度比内存要快得多。处理器在进行数据处理时,会首先从 cache 中提取数据和指令,唯有在发现 cache 中没有所需数据时才向主内存发出请求,要知道从主内存中提个数据,可能需要浪费多达 200 个时钟周期,这对处理器这种高速设备而言绝对是不太能忍的,所以你看当代 CPU 的 cache 命中率有多高。
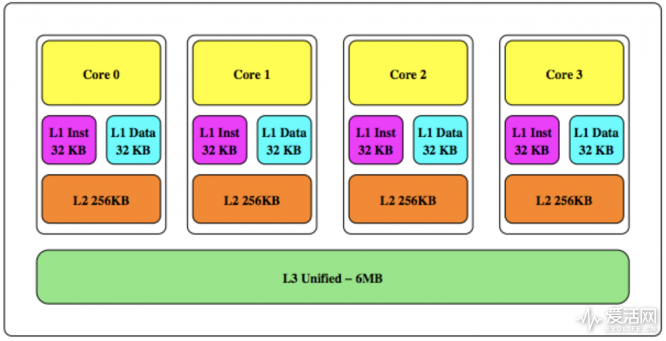
当代处理器都采用多层级 cache 方案, Cache 中的存储基本单位是 line,每条 line 包含固定字节数(如下图)。比如 i5-3470 的 cache line 尺寸为 64 字节。另外作为共享 cache,所有 cache 数据的副本在此处都有一份(至少 Intel 处理器是这样)。所以如果我们尝试从 L3 擦除一些数据,则其他各级 cache 的数据都也可以被移除——这是 FLUSH+RELOAD 攻击的基础。
比如上面这张图是 Intel 酷睿 i5-3470 处理器的 cache 架构。其 cache 分三级,分别是 L1、L2 和 L3 缓存,L1 离处理器核心最近,速度最快,容量也最小,L3 则离处理器最远,容量相对也更大——此例中是 6MB。从 2008 年 Intel Nehalem 架构开始,Intel 的所有多核酷睿处理器就有了共享 L3 缓存,无论这个处理器有多少内核均能共享 L3 至 LLC(Last Level Cache,末级缓存)中的所有数据,这也间接降低了攻击实施的难度。
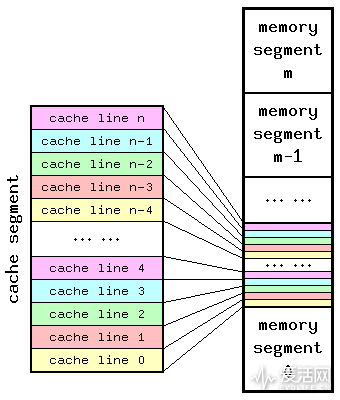
假设有这样一个目标进程 1,为了让它和我们构造的恶意进程 2 进行 page sharing,就将内存映射函数 mmaps 应用到目标可执行程序,令其进入恶意进程 2 的虚拟地址空间,完成映射文件的内存镜像共享(需保证两者在同一物理处理器上运行,可令其位于处理器的不同核心之上)。
攻击第一步,让恶意进程 2 监控某个特定的 cache line,并将其内容从 cache 中擦除;第二步,恶意进程 2 等待一段时间;第三步,恶意进程 2 重新载入刚才的那条 line。如果说载入这条 line 的时间比较久,就说明应该是从主内存中载入的(因为主内存很慢),最主要的是说明在等待过程中目标进程 1 并没有尝试载入这条 line;但如果在这一步中,恶意进程 2 载入这条 line 的时间很短,就说明目标进程 1 刚才也尝试过载入这行 line(因为目标进程 1 载入过之后,这部分数据就已经写到了 cache 中,而 cache 是很快的,所以恶意进城 2 载入这条 line 的时间就很短了)——撞上了!
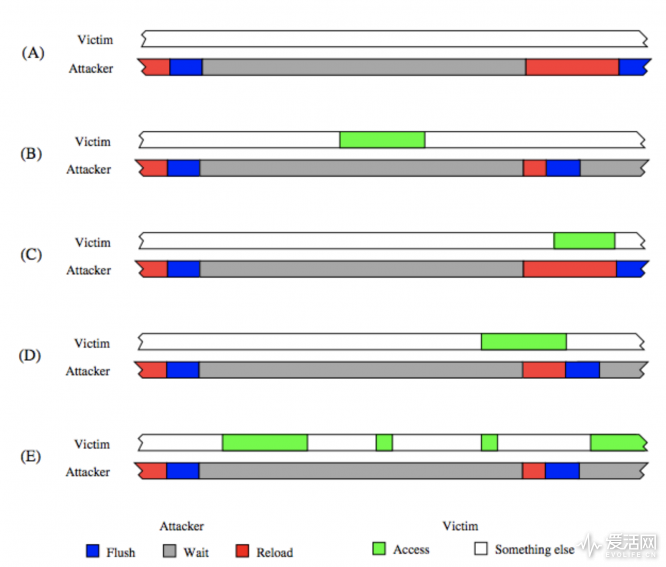
如此循环往复,如上图所示,这样一来就能得知哪些数据被存取过。这就是所谓的 FLUSH+RELOAD L3 cache 攻击。当然了,这种攻击还是存在精度问题的,比如说上图 C 的情况,恶意进程请求载入某条 line,在极短时间内目标进程也恰巧请求载入这条 line,这样观测到的结果就会有问题;另外还需要考虑一些处理器的性能优化方案的噪声干扰,比如说现在的处理器的空间局部性实现的数据预取(prefetch),还有像是分支预测,这要求在设计攻击程序(建议采用循环体之类以内存访问相对频繁的为目标,如上图 E)和对结果进行分析的时候有过滤策略。

比如像上面这样,其中第 14 行 cflush 就是从所有 cache 中擦除某行 line;另外,如 mfence、lfence 这些指令实现指令流的串行序列化,避免并行和乱序执行的出现。这篇 paper 还特别举了攻击的实例,以这种攻击方法从 RSA 实施方案 GnuPG 中获取私钥。按照这篇 paper 所说,平均而言,这种攻击方案通过观察单独的一个签名或加密轮,平均就能恢复密钥 96.7% 的 bits。
至此我们不难看出,现代处理器特别是多内核处理器为了提升性能,大部分都采用了多级缓存设计,而各大处理器厂商更是投入巨资去研究和提升缓存命中率,然而这样的设计恰恰存在漏洞。那么,现代处理器如果没有缓存或者不共享缓存,是不是就会幸免于难?在热核时代,答案当然是否定的——还记得我们开篇所说么?Meltdown 和 Spectre 包含 3 个漏洞,缓存只是其一,乱序执行接踵而来。
要发表评论,您必须先登录。



叹为观止!终于有人讲明白这两个漏洞是怎么回事了
典型的理论分析吧。。。
看来amd说自己安全保险也有吹牛的成分在里面
9代应该也是暗藏隐患,毕竟很早就开始设计定型了,也许10代都不一定是重新设计的
nb
炸裂
+1
叹为观止,终于有人讲明白这两个漏洞是怎么回事了
叹为观止,终于有人讲明白这两个漏洞是怎么回事了