


 3
3 1
1 3
3


从现在知道的信息来看,应该还是ARM架构,除了ARM也没什么适合移动端的新架构。

 登录|注册
登录|注册






从李世石到柯洁,AlphaGo将人类的围棋战局搅了个翻天覆地。谷歌的DeepMind,向世界证实了人工智能的力量。现在,这个从人类这里学会下棋,并超越所有人的AlphaGo又升级了。
周三,DeepMind发布了新一代的AlphaGo Zero,一个不再需要人类,基于自学而不断成长的AlphaGo。人工智能,离自己创造通用算法,攻克最艰深的科学问题,比如自己设计药品、创建更精确的气象模型,都更近了一步。

上一版打败了柯洁的AlphaGo,已经展现了超人类的围棋能力,但是,它依旧需要人类知识的帮助,比如,它学习的超过十万盘人类棋局,作为它知识体系的基础。而现在的AlphaGo Zero,仅仅需要程序员输入最基本的围棋规则,就可以摸索出完整的围棋下法,并超越前者。
从DeepMind在《自然》杂志上发表的论文来看,它的所有练习,都由和自己下棋来完成。一开始,只是随便落子。就好像所有刚刚下围棋的小朋友一样。不过,很快,Zero就自己发现了围棋一些成熟定式,从业余选手转化为专业棋手的下法。
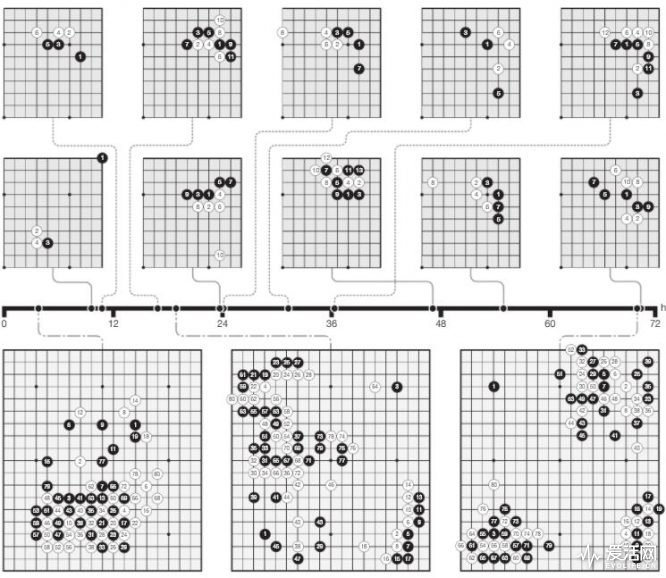
上一代的AlphaGo有两个分开的学习模型,一个专门用来评估当下的形势和棋局,另一个给出可能的下几步走法。而后,AlphaGo从中挑选出可能的走法,让这些走法在第三个模块中实验,模拟出不同的结果。
Zero则是单个的、更加强劲的人工神经网络,在评估棋局的同时,给出新的建议走法。它的整套搜索模块,都变得更加简洁。在自己和自己下棋的过程中,Zero胜利的一方就会发现那些不同的定式,自我进行选择、然后系统,再下、再升级,以此类推上百万次。
三天的时间,AlphaGo Zero已经从零基础者,变成打败李世石的版本;40天后,它与打败柯洁版本的AlphaGo的胜率,达到90%。毋庸置疑,Zero是人类历史上,最强的围棋选手了。

完全不需要人类的智慧、知识、帮助,Zero有了自己从零开始建立规则、寻找原理的能力,完成了质的飞跃。
Zero除了是一个更佳的棋手,作为一个人工智能,它还有着其他比前代AlphaGo更好的性能。首先,它所需的计算能力更小。相比上一代需要48个TPU,Zero需要的只有4个。当你需要将AlphaGo的能力放到其他更实际的领域中去的时候,它所节省的运算容量,将带来更大的便利性。
其次,作为一个自我学习的模范,Zero在开发新的算法的时候,将不再需要大量的数据做支撑,在现阶段的AI研究中,又是一大突破。目前我们看到的AI的结果,很多都是在大量的廉价计算能力和数据的基础上实现的。它能够给让AI实现新的功能,却让它同时缺乏持续性。
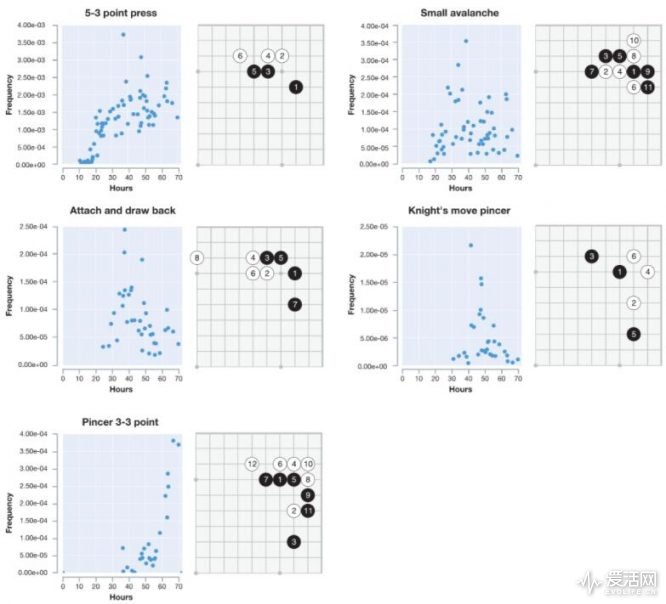
Zero的进化,让人们看到了仅仅依靠算法,就达到重大突破和进步的可能性。即使从一些相对陈旧的信息中,人工智能也可能发现全新的、人类从未开发到的方向。
不过,Zero是一个搜索不同的可能性,选取最佳路径来实现的模式,依旧展现出了AI技术的局限性。毕竟作为一个有规则的棋类游戏,对于计算机来说更有优势。阿尔伯塔大学的教授Martin muller虽然也认为Zero的简洁设计近乎完美,但是在围棋的限定规则之下,自我学习是不够的。
当人工智能完成一个需要多方面考量的挑战时,它就会陷入迷惑之中。比如安装一个宜家的沙发、设计一趟旅行。在这些事情上,人类更加依赖抽象、逻辑推理的能力。
当然,着绝不代表Zero的技术不能用到更多的世纪开发中。时尚,谷歌已经用这些算法节省了不少的数据中心冷气钱。DeepMind在上一个季度,为整个Alphabet(谷歌母公司)集团,提供了价值四千万英镑的服务。

DeepMind还打算加AlphaGo Zero的能力用到气象预测、蛋白质分子折叠等问题上。谷歌的机器学习,也显示投放更精准的广告的能力。
最后,AlphaGo Zero也会给被它打击的人类围棋,输入一些新鲜的血液。作为第一个被AlphaGo打败又加入DeepMind的专业棋手,樊辉表示,AlphaGo的围棋虽然看上去真的很像是一个围棋高手,却有透露出更加自由的气象。无需局限于人类的知识之中,Zero给棋手们带来了全新的走法,新到连AlphaGo自己都想不出来的那种。
要发表评论,您必须先登录。



可以的
天网准备上线~
单细胞进化成霸王龙还是需要些时日的。