
i5更比i9强 英特尔12代处理器暨ROG Z690 HERO评测报告

 登录|注册
登录|注册







在12代Adler Lake-S可以说是最近10年变革最大的intel处理器,我在这里罗列最为核心的几点变化:
• Golden Cove是多年来核心架构IPC效能最大的一次提升;
• 第一次在桌面使用性能核心/效率核心的混合架构;
• 第一个10nm (intel 7 Superfin增强)工艺的处理器;
• 第一个支持DDR5的桌面处理器;
• 第一个支持PCI-E 5.0的桌面处理器。
可以说intel对其抱有有极高的期待,可以说是intel最重要的一次产品发布。于此同时玩家和消费者也对其也有很大的兴趣,但也存在一些疑问:
• 12代处理器的IPC效能如何,比Zen 3快多少?
• 12代实际的生产力性能如何?
• 12代实际游戏性能如何?
• i5真的可以干i9么?
• 大小核心是坑不?调度有没问题,会不会游戏跑到小核性能不升反降?
• 12代超频性能怎么样?
• intel 7工艺功耗和温度如何?积热不?
• DDR5和DDR4有什么区别,延迟大不,怎么选择?
• 12代处理器值得购买不?
• 12代平台主板如何选择?
我们将在本文详细的分析并解答大家的这些问题,本文长度较长,完整阅读可能需要20分钟以上,数据量较大,建议使用电脑或者平板阅读。
在12代Adler Lake-S处理器评测之前,我们先梳理一下目前桌面处理器产品竞争力情况和市场格局。
AMD的Zen 3是2020年11月发布,至今差不多已有一年,其完整的对抗了Comet Lake 10代和Rocket Lake 11代处理器,特别是对CML,基本是代差级别的降维打击,现在看来还要打Adler Lake 12代,其主要优势在于:
• 相对Comet Lake和Rocket Lake更好的IPC;
• 更大的L3 Cache可以带来更好的游戏性能;
• Chiplet的多die方式,使得核心扩展很方便和相对低成本,这样就有更好的多核心性能;
• 台积电7nm工艺带来更低的功耗,对于主板的要求也更低。
但Chiplet方式对于Zen 3来说是成也萧何,败也萧何,虽然这样可以已更为简单和低成本的方式扩大核心数量规模,但这种chiplet方式也有明显的缺点:
• 对于Ryzen 9这样2个Die的型号,跨die核心通讯延迟高;
• 外部独立的CIOD芯片,导致内存延迟偏高,同时FCLK上不去;
• 再就是单个Die 8个核心,最低屏蔽到6个,而没更低型号,这样型号覆盖不能下潜到主流及入门市场;
• 首发Zen 3并无集显,后续的APU 5600G/5700G无论是核心数量还是GPU规模也都过高,对于亮机办公而言过于奢侈,无法覆盖真正需要集显的目标用户。
这样使得比5600X/5600G更低规格还是依靠Zen 2苦苦支撑。AMD就是这样在市场占大头的中低端市场是吃闷亏的,但玩家群体只看见Zen3的光鲜,却很少注意得到中低端的尴尬,他们只知道喊AMD YES。

而对于Rocket Lake,虽然同频IPC要略差于Zen 3,但得益于14nm+++工艺更好的性能,可以实现更高的频率,在核心数量相同的情况,还是有稍好的性能。
当然这个仅仅是在相同核心的情况下,Rocket Lake在面对更多核心的5900X/5950X时候,相比多线程性能还是可怜无助的。
14nm+++工艺虽然频率上的去,但面对RKL的芯片规模还是太过于勉强,实现高频的代价则是高功耗,这样给主板供电和散热带来更高的要求,这样使得平台需要额外的投入。这样的高功耗在一定程度都有妖魔化的趋势,让普通玩家都不太乐见。
AMD优势在高端Zen 3,而Intel的优势在于更为下沿的产品线覆盖更低:在千元出头价位,在i5不带K实际性价比极高,实际是无竞争对手的,Zen 3在5600X以下就是空白。虽然i3 Pentium还是Skylake,但吊打Zen 2还是无悬念。
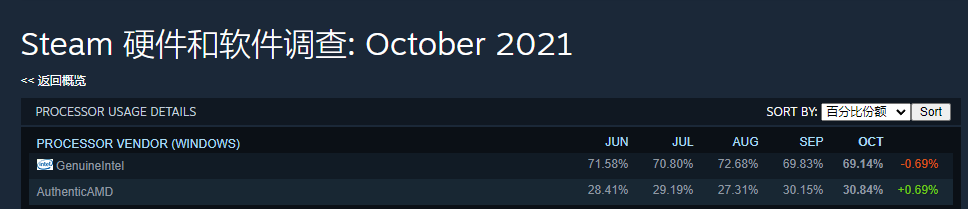
看Steam硬件调查数据,AMD在玩家群体里的占有率已经超过了30%,玩家群体很大程度认可了AMD。
但看整个桌面处理器的市场占有率,AMD反而从去年Q2的19.2%下降到今年Q2的17.1%。 下降的原因一方面是收到上游供应链供货不足的影响,另一方面重要原因就是AMD的市场布局是头重脚轻,虽然Zen 3无限风光,但中低端没有Zen 3这样有竞争力的新品,还是依靠Zen 2的遗产苦苦支撑。

在10月22日刚刚发布的intel财报,虽然CCG(客户计算部门)整体营收下降了2%,但主要还是被笔记本拖累,台式机增长了20%,并且平均售价上升了4%。很明显intel桌面市场基本盘还是稳定的,但相对于Zen 3发布到现在这段时间依然是intel最为痛苦的时期。
自打 AMD Zen 3 发布后,Intel 感受到的压力是与日俱增,桌面、服务器以及笔记本市场都受到来自 AMD 产品矩阵的冲击。不仅于此,相对于上市的产品而言,Intel 面临的另一个困境是制造工艺上已经不再占优,性能耗电比竞争力不再,这使得 Intel 或者说 x86 阵营得以在主流 PC 不败的地位遭受前所未有的冲击。例如 Apple 正逐渐切换到采用台积电生产的 Apple Silicon 处理器,这对 Intel 来说是一个非常危险的警号。
我们都知道,Intel 本质上是一家工厂,同时也是美国目前为数不多的垂直大型芯片制造业龙头,是高端制造业中的重中之重,当自己生产的产品也被本国长期合作的企业放弃时,那就是到了非改不行的地步了。
Intel 当前最大的问题是制程,由于制造工艺方面出现了落后于竞争对手代工厂的情况,因此摆在 Intel 面前的最大挑战首先是如何尽快采用更先进的制程,以及如何从架构着手让性能/耗电比指标实现逆转胜。
相比三年前的了无生趣,PC 正迎来一场史诗级的重新提速,这是一场旷世的防守与反击博弈,如今,这场史诗级的博弈正徐徐展开其第二篇揭幕战的序章。

Intel 历史上也出现过产品部分竞争力不敌对手,那是在 AMD K7/K8 vs Intel Pentium 4 的时代,距今差不多 20 年,幸运的是,Intel 赶上了笔记本崛起的浪潮,凭借 WiFi 和 Core 架构成功卡位并在随后的桌面大战中凭借 Conroe 收复失地。这说起来好像化解得挺轻松的,但是当年的动静可是非常大,以至于出现了 Intel CEO 当众下跪的局面。
来自 Intel 以色列海法团队的 Yonah 和 Conroe 是扮演救主的重要角色,前者让 Intel 把笔记本市场牢牢掌握在直接手里,后者则是一洗 Netburst 架构在桌面市场的性能/耗电颓势。
如今,这支 1974 年就成立的团队再次出击,它们这次祭出的是代号为 Alder Lake 的第十二代酷睿处理器。
对于研发阶段的产品或者技术冠以各种架构代号是司空见惯的,曾经在 Intel 任职 20 年的 Francois Piednoel 将将取架构代号的原因归结为两个:保密以及让媒体大惊小怪,当年 Intel 曾经于 IDF 密室内在媒体不知情的情况下演示过 Conroe,由于屏蔽了其中的运算单元,以至于媒体以为跑的是更好的 Yonah,后来 Intel 还把这个“更好的 Yonah”发给 OEM 和 ODM,大家浑然不知手头测试的是 Intel 全新的下一代处理器。
相对于多年前名称差别较大的代号名称,Intel 现在的架构代号大都以 Lake 或者 Cove 结尾,要区分这么多 cove 和 lake 对读者来说是相当困惑和考验记忆力的事情。
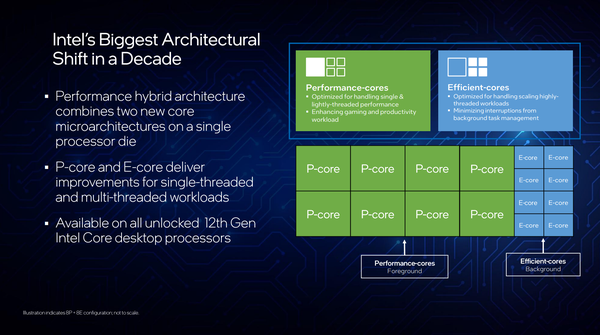
名字取自美国西部华盛顿州一处湖泊的 Alder Lake 满血版具备 8 + 8 = 16 个内核,其中 8 个高性能内核(P-core,内核编号 0-7)的代号是 Golden Cove,另外 8 个高效内核(E-core,内核编号 8-15)的代号是 Gracemont。
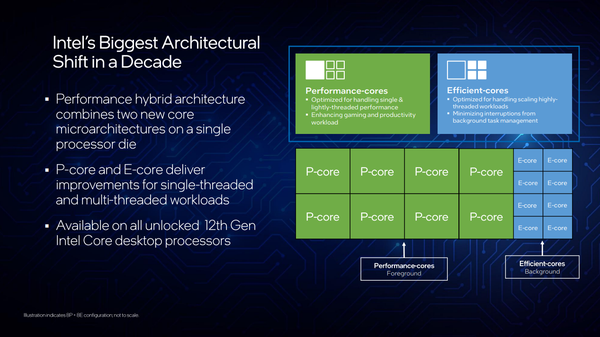
Intel 将这种大小核混编的技术命名为 Intel Hybrid(英特尔混合)或者 Hybrid Computing Architectures(HCA),以便和 ARM 的 big.LITTLE 区分。
在 Intel 提交的 perf(linux 下的性能特征分析工具)补丁里,P-Core 属于 Core 类型,E-Core 属于 Atom 类型,很多性能计数器事件是分立的。例如,想要采集 IPC 数据的话,采集的指令性能事件需要单独列明,例如 cpu_core/instructions 和 cpu_atom/instructions,当然如果是 LLC(第三级缓存)、能源这类事件则是统一的。
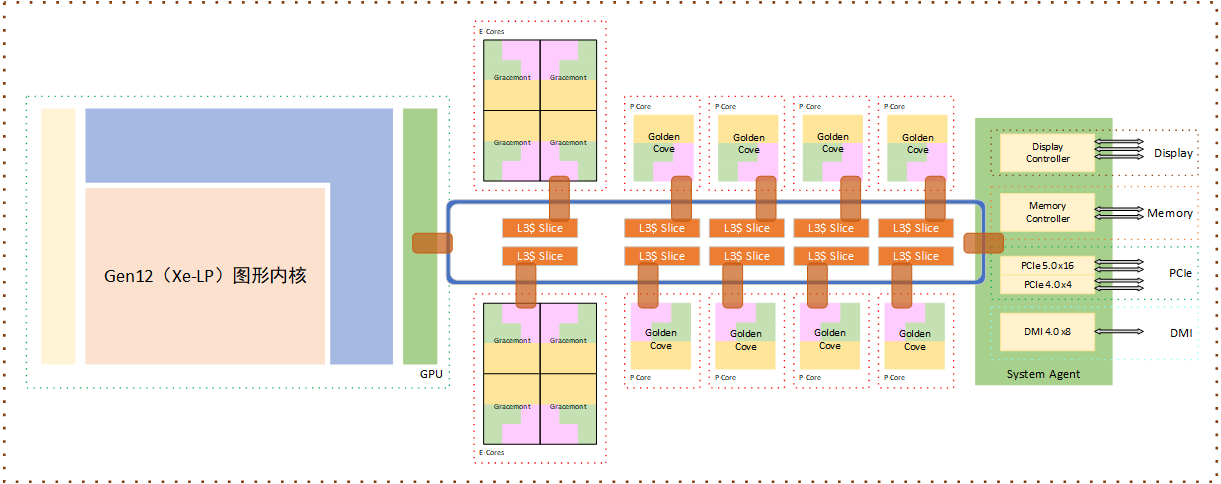
从处理器的整体架构来看,Alder Lake 相当于传统 Core 系列处理器加挂了两个四核 Atom 内核簇,每个 Atom 内核簇共享一块 L2 Cache,然后分别挂在 Ring bus 上,与 P-Core 一起共享 L3 Cache。
在内核拓扑关系工具 lstopo 中 Core i9 12900K 呈现的层次关系如下:
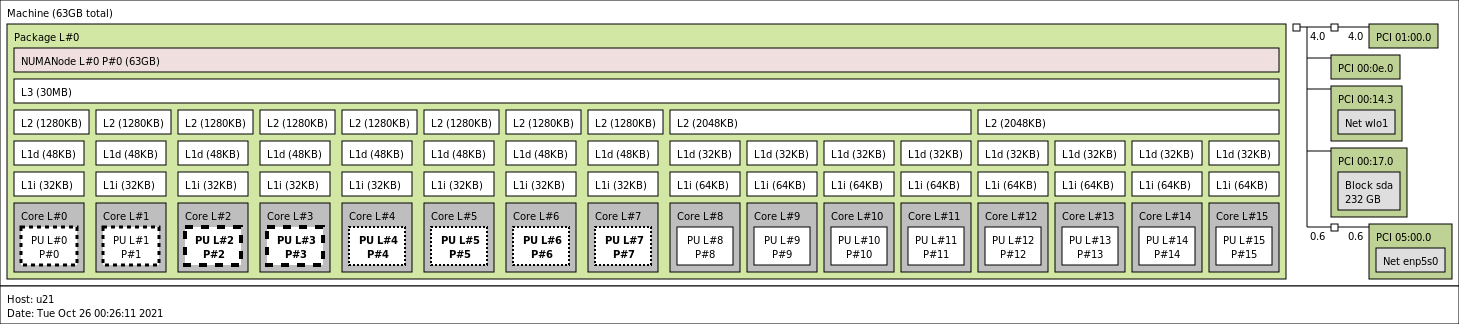
和扮演救火队员角色的 Rocket Lake 相比,除了 GPU 基本保持不变(都是 Xe-LP 架构,型号名称从 UHD750 变为 UHD 770,GPU 频率有大约 400MHz 提升)外,Alder Lake 在 CPU 内核微架构(P-core、E-core)、PCIE 总线、DMI 总线、内存子系统上都有很大的变化。
Golden Cove 和 Gracemont 虽然都是 x86 指令集处理器,但是在微架构层面上存在巨大差别,前者具有更深、更宽的流水线,频率设定较高,强调高性能;后者的角色按照设计理念是做一些轻体力活为主,强调低能耗,Intel 为此还专门加入了一个名为 Thread Director(线程导向器)的硬件线程导向器,这个导向器的目的就是把各种线程按照其负荷递交给不同类型的内核,具体的线程导向器策略我会在后面具体说到。
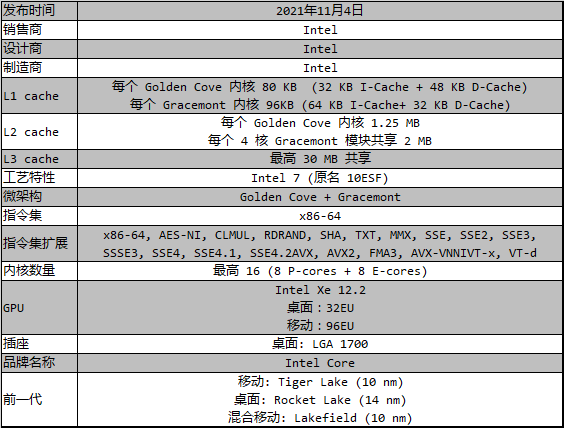
Golden Cove 虽然属于十一代笔记本酷睿(Tiger Lake)里 Willow Cove 的升级,但是它在某些方面都有巨大的变化,例如乱序指令窗口方面,ROB(重排序缓存)的大小可能是 x86 史上最大的增幅,充分利用了新制程晶体管密度提升带来的好处。按照 Intel 的说法,Golden Cove 的 IPC(每周期指令)性能相较上一代(Willow Cove)提升了 19%。

Gracemont 主打低能耗,但是本身的性能还是可以的,它属于 Atom 阵营里的第四代乱序执行架构,性能并不亚于三年前的主流桌面处理器。
更多的内核以及更宽的指令执行能力带来的问题是内存带宽需求增加,Intel 为 Alder Lake 配备了同时支持 DDR4 和 DDR5 的内存控制器,前者的价格相对较低,而后者具备更高的内存带宽。
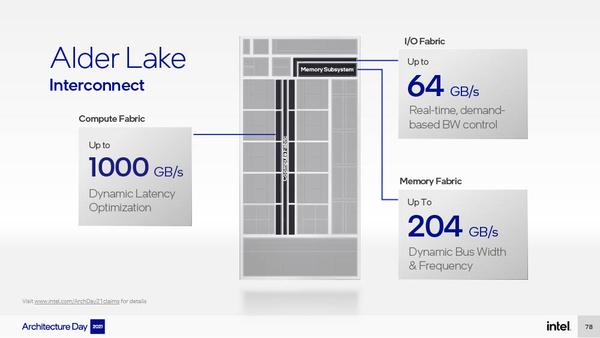
由于集成了多达 16 个内核以及大量高带宽部件,Intel 为 Alder Lake 的内部互联提供了 Tiger Lake 同款的 1000GB/s 的双环路互连总线,理论上满载的时候每个内核可分配到的带宽是 62.5GB/s,当然这只是理论值,因为全核跑向量计算的时候内存带宽更容易成为瓶颈。
我用 MicrobenchX 的 C2C 测试了内核时延:
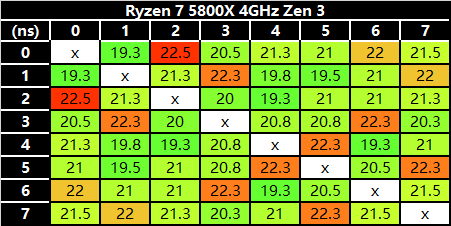
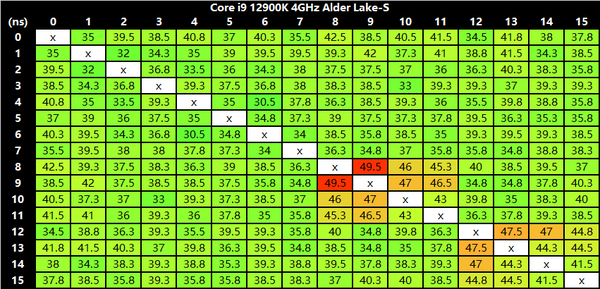
从 C2C 时延测试来看,Alder Lake 的核心间时延要比 Zen3 高不少,其中 E-core 的 4 核簇内部之间似乎存在较高的时延,这有点出乎意料,要知道它们是有一个 L2 cache 共享数据。
整体架构:大小核心是坑么?
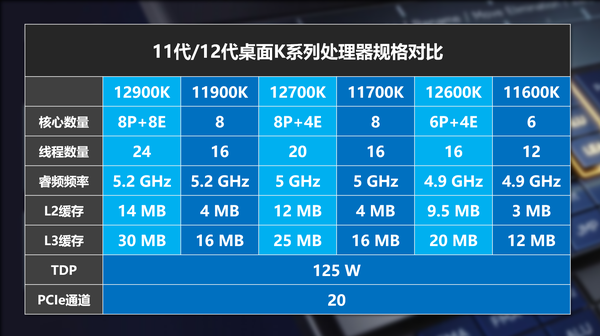
11代的i7和i9都是8C16T,主要是体质和频率的差别,而十二代i9和i7都是8个P Core,但e Core分别为4个和8个,再加上频率和缓存容量的差距,这样的区隔空间刚刚好。

这是ADL的dieshot,中间8个蓝色的是Golden Cove核心,每个GDC核心对应1.5MB L2缓存和3MB L3缓存。右边青色的8个是4个一组的GMT核心,每组有2MB L2缓存和3MB L3缓存。这些核心由环形总线连接。最右是UHD核心显卡和解码引擎部分,依然是32个EU。左边是SA、内存控制器和接口(左下紫红),PCIE/DMI控制器(最左绿色)和显示输出部分,需要特别注意的是PCIE 5.0控制器部分占用了很大的核心面积。
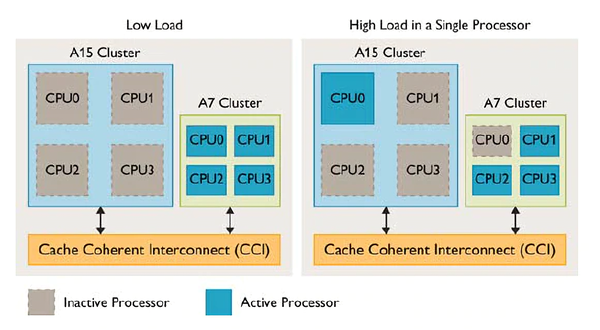
Intel在ADL开始在桌面引入了P-Core性能核心和E-Core效率核心的概念,其实简单点说就是Big.Little大小核,这也不是什么新东西,在ARM平台12年的A15+A7就是这样的架构。但Android的核心调度算法做的并不算太好,经常会出现重载任务,小核累死,大核围观的情况。这样痛苦的经历让不少人有了大小核PTSD,并对ADL的混合架构充满怀疑。

Alder Lake 架构是 Intel 历史上第一个实际上市的混合核心架构,在这之前该公司曾经有一个代号 Lakefield 的 x86 混合内核项目。Lakefield 是一个移动 CPU,大小核分别是一个 Sunny Cove(在 Tiger Lake 或者说十一代移动酷睿处理器中采用)和四个 Tremont,包括微软的 Surface Go 和三星的 Galaxy Book S 都曾经被表示会采用该处理器。
Lakefield 采用堆叠芯片封装,其中的 Compute Die 或者说计算芯片采用 Intel P1274(10 纳米)制程,里面的大核 Sunny Cove 内核面积大约是 4.5 平方毫米,而小核 Tremont 只有 0.88 平方毫米,两者面积存在巨大差异,按照 Intel 的说法,每枚小核的性能相当于Sunny Cove 的七成。由于面向的是 Intel 一向竞争力最弱的移动设备,因此 Lakefield 在 Intel 的产品线中并不起眼,乃至它被取消了也没有引起什么波澜,存在感很低。
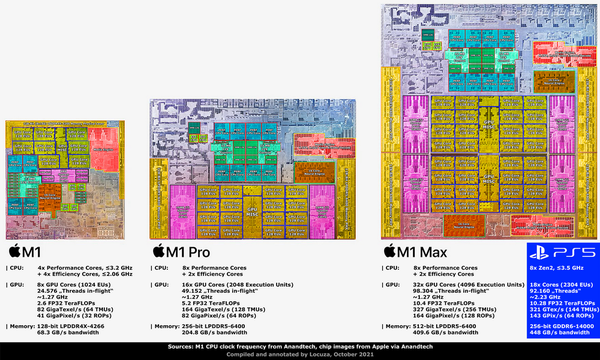
另外,现在Apple的当红榨汁机M1系列也是混合架构,但从Apple M1 Pro和MAX的8个P-core+2个E-core核心配置方式看,其设计的主要目的也应该是降低待机和轻载时候的功耗。
但ADL-S是作为桌面处理器,对于功耗其实并没那么敏感,其主要目的是两个:

在ARM平台,Big.Little已经差不多10年,但任务调度一直都是老大难问题,,至今依然没有太大改善。甚至不少人对Android的Big.Little产生了PTSD.而intel为了解决这个问题,在ADL上设计了intel线程调度器(intel Thead Director)的专用微处理器。这个部分是intel和微软共同研发,其主要有三大任务:
• 以纳秒级别的精度监控每个核心实时指令状态; • 并将工作负载实时反馈到操作系统,让系统可以优化安排任务决定; • 可以无需用户干预的情况,基于功耗温度和操作条件进行自适应调节。

一般任务分配原则是这样的: 优先任务会被安排在P-core,后台任务在E-core,如果高优先任务占满所有P-core,就会再分配到E-core,如果所有E-core也都被占满,就再会分配到P-Core的超线程上。
Android最主要问题问题是经常大核发呆,而用小核心跑前台重载任务。而ADL-S这样的桌面平台不太用像移动端考虑功耗,也就基本不存在这样的问题,直接简单暴力能大就大,不够再小。
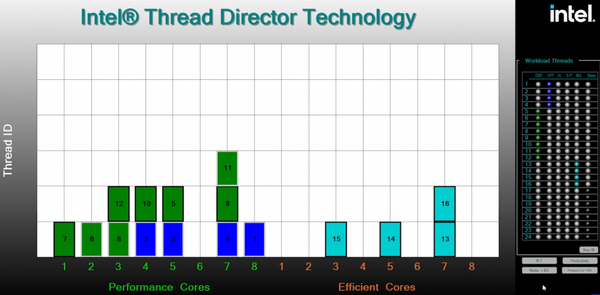
在下面运行典型媒体/内容创建软件的演示中,深绿色框代表主要执行标量指令的线程,而深蓝色代表主要执行向量指令的线程。这两个线程都被优先考虑到P-core。浅蓝色框代表后台任务则是优先安排在E-core。
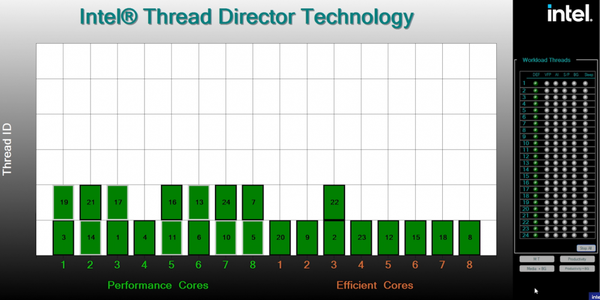
而全核心多线程任务,也和预期一样,先塞满P-core,其次E-core,再P-core超线程。并且在这样的情况整数比较倾向分配给E-core,而复杂度更高的浮点运算则交给P-core。当然,这个仅仅是策略,实际表现如何,我们稍后还是依靠具体测试来说明。
接下来让我们看看 Alder Lake 混合架构里两种内核的细节。
如果不考虑 Larrabee 这个物种的话,Intel 的 x86 产品线可以分为两大品牌系列,也就是 Core 和 Atom,分别对应高性能和低耗电。第一个 Atom 诞生于 2008 年,比 Core 晚了两年。当时正值移动设备迅速崛起,Intel 全副身家都押宝 x86,Atom 则是其中被寄予厚望的品牌之一。
由于缺乏良好的生态以及配套服务,Atom 最终在手机市场败下阵来,不过这个品牌并未消亡,由于 x86 在工业领域具备非常好生态,因此 Atom 都被做成工控机、路由器、NAS 等不需要高性能内核的应用场合。
最初的 Atom 微架构代号是 Bonnell,之后有名为 Saltwell 的衍生微架构,这两代都是属于顺序执行流水线,虽然省电,当时性能真的一般。
第三代 Atom 微架构名为 Silvermont,引入了乱序执行,衍生微架构有为 Airmont。
自此开始,所有的新 Atom 微架构代号都带有 “-mont” 的后缀。
我们把 Sivermont 视作第一代乱序执行 Atom 微架构,之后分别有 Goldenmont(衍生微架构为 Goldenmont Plus)、Tremont 以及现在 Alder Lake 里的 Gracemont,因此 Gracemont 已经是第四代乱序执行 Atom 微架构。
Alder Lake 是第一个采用 Gracemont 内核的芯片架构,满血的 Core i9 12900K 包含有 8 个 Gracemont 内核,每 4 个 Gracemont 构成一个内核模块共享 2MB L2 Cache。
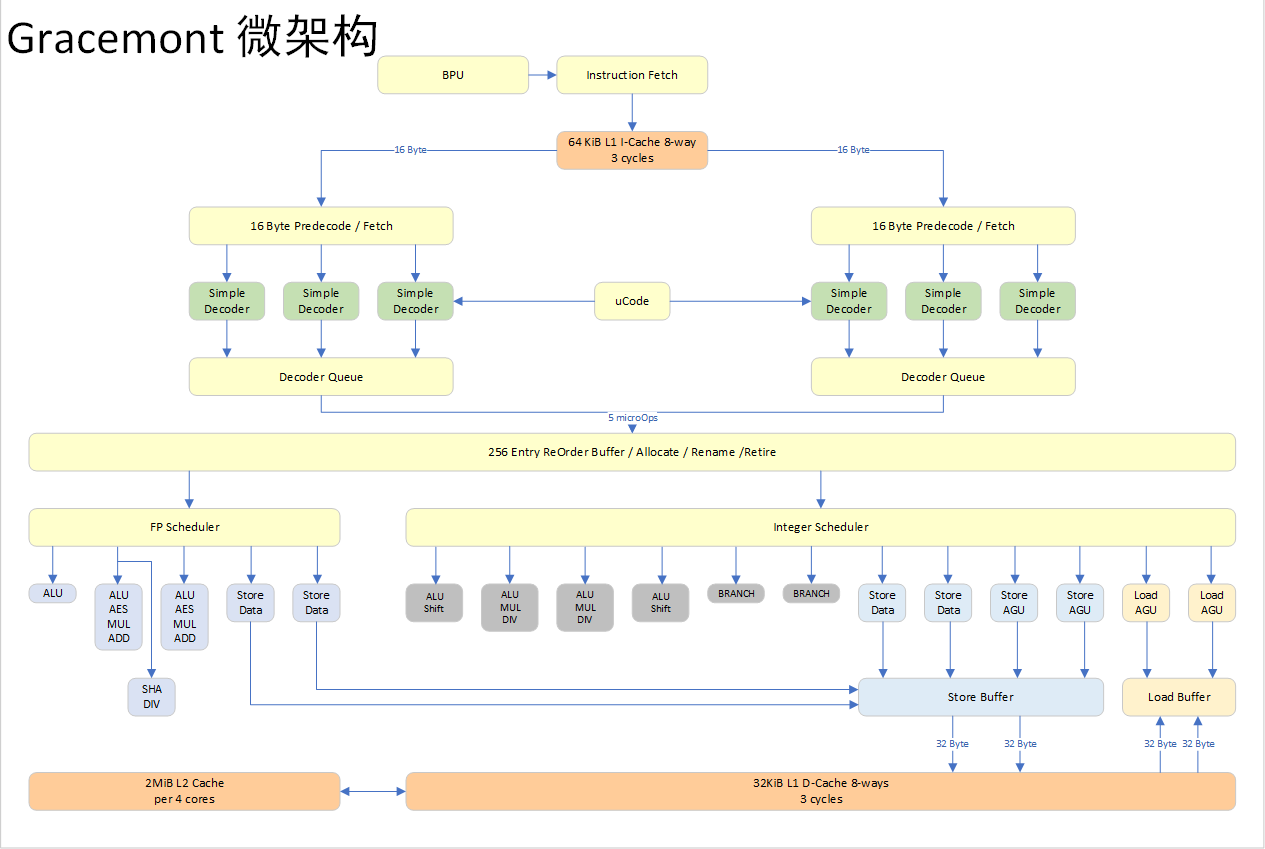
在 Alder Lake 中,每四个 Gracemont 组成一个 Atom 簇,共享一块 2048 KiB 大小的 L2 Cache,每个 Gracemont 拥有 64 KiB L1 指令高速缓存(两倍于 Tremont)和 32 KiB L1 数据高速缓存。

比较特别的是,Gracemont 引入了名为 OD-ILD 的按需“指令长度”预解码器设计。众所周知,x86 属于 CISC 或者说复杂指令集计算机,其指令长度可以是 1 个字节到 15 个字节,进入解码器之前需要确定指令的边界或者说长度。Gracemont 在L1 指令缓存里存放了指令长度数据,可以在指令第二次拾取时绕过预解码阶段,直达指令解码器前的指令队列上,这样的设计可以节省部分周期和耗电。
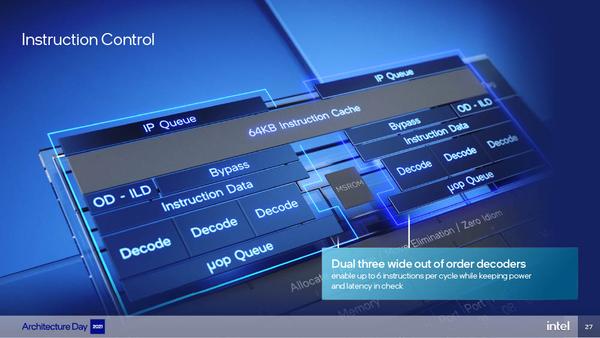
Gracemont 采用了双解码器簇的设计,每个解码器簇各有三个简单 x86 指令解码器。虽然看起来一共有六路解码,但是两个解码器簇合计只能向下游输出 5 个 RISC 风格的微操作。与之相比,Gracemont 的直系上代微架构 Tremont 也具备一样的双 3 路解码器,但是只能做到输出 4 个 RISC 风格微操作。
按照之前 Tremont 微架构发布时候的说法,这种双解码器簇对于 Atom 来说效果比 Core 里使用位操作高速缓存(micro-ops cache)的做法更好,既能做到 6 路指令解码又能降低芯片面积。
从较大的 L1 指令 Cache 到双解码器簇设计来看,Intel 是下了大功夫来改善 Gracemont 的前端瓶颈,原因是它的后端微架构实在有点炸裂。
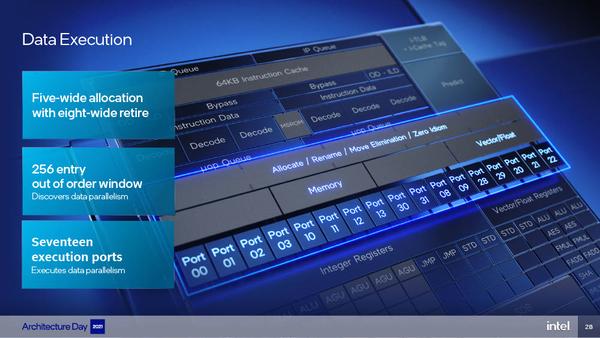
在后端方面,Gracemont 的重排序缓存可以容纳 256 条目,可以向执行单元同时派发 5 个微操作,相比之下上一代的 Tremont 指令窗口是 208 条目,可以向执行单元同时派发 4 个微操作。在执行单元端口数方面,Gracemont 和 Tremont 分别是 17 个(12 个整数 + 5 个浮点)和 10 个(7 个整数 + 3 个浮点),指令并行能力有所提升,事实上如此众多的执行端口也是 Gracemont 微架构中最让人惊讶的地方。
e-core 和 p-core 同时开启的时候,指令集支持能力是完全一样的,可以支持 AVX2 或者说相当于 Haswell 的级别。
但是 p-core 或者说 Golden Cove 其实是内建了 AVX-512 指令支持,当我们把 E-core 关闭后,现在的 BIOS 能够让 P-core 那边的 AVX-512 开启。
关闭 E-core 后,uncore 时钟频率(原为 3.6GHz)也会得到提升,例如在 Windows 下会 uncore 提升到 4.7GHz,而在 Linux 下 uncore 提升幅度会低许多,只有 3.8GHz。
既然谈到了 P-core,那么我们直接转到 P-core 的架构讨论吧。
正如我们前面所说的那样,Golden Cove 物理上具备 AVX-512 指令集的硬件支持,但是其启用条件是要在 BIOS(新版)里关闭所有 e-core,这意味着目前的 P-core + E-core 组合对于希望能实现 AVX512 的用户来说未必是最佳选择,英特尔倒是提供了 6P + 0E 的物理纯 P-core 版本,例如 Core i5 12400。
让我们从流水线的前端(取指和解码)说起。

Golder Cove 的 L1 指令高速缓存和上一代的 Willow Cove 相比未有变化,都是 32 KiB,但是与之关联的指令页表缓存(I-TLB)是做了升级的,其中 4K 页表的条目数从 128 增加到 256,2M/4M 页表的条目数从 16 提升到 32。
在分支预测器方面,Golden Cove 的目标分支缓存(BTB)条目数增加了一倍多,从 5K 增加至 12K,相比较之下,AMD 的 Zen 3 不过是 6.5K、Willow Cove 是 5K。
更大的 BTB 原因很简单,Golden Cove 的 x86 指令解码器达到了 x86 史上之最——多达 6 + 1 个,而它的主要对手 Zen 3 只有 4 个,更是两倍于 Willow Cove 的两倍。
为了降低更多指令解码器带来的耗电和时延问题,Intel 将微操作缓存(micro-ops cache)的大小从 Willow Cove 的 2.25K 条增加到 4K。按照 Intel 的说法,由于具备微操作缓存设计, Golden Cove 的解码器有 80% 的时间都是处于时钟门控(clock-gating,单元时钟被关闭,相当于熄火)状态,有效降低了这部分电路的动态功率。
为了喂饱 6 个解码器,Intel 把指令拾取带宽从每周期 16 字节提升了一倍达到 32 字节,与 Zen 3 持平。
在微操作高速缓存方面,现在可以每周期发送 8 个微操作,同样达到了对手 Zen 3 的水准,相比之下 Willow Cove 只做到了 6 个微操作。
位于解码器和微操作高速缓存下游的微操作队列(uop-DQ,或者说分配队列——Allocation Queue)如今也被加大了:
对于单线程应用,微操作队列可以存放 144 个(Willow Cove 是 70 个); 对于支持 SMT 的应用微操作队列则只是增加了多了两个(70->72)。
Golden Cove 的调度器具备 6 个分配端口以及 12 个执行端口,相比之下上一代的 Willow Cove 是 5 个分配端口和 10 个执行端口。AMD 的 Zen 的调度器采用了类似 Apple M1 那样的整数、浮点分离式设计,可同时调度 8 条整数指令和 6 条浮点指令。某种程度上,Zen 系列和 Apple M1 这方面长得有点很像,都采用了分离式调度器的设计。
在 ROB 重排序缓存方面,Golden Cove 达到了 512 条目,AMD Zen 3 是 256,Willow Cove(Tiger Lake,10nm)和 Cypress Cove(Rocket Lake,14nm+++)都是 352。
Apple M1 的 ROB 有媒体说高达 600 个,但是也有人(Dougall Johnson)认为其 ROB 采用的是一种合并式的新设计——大约有 330 条目,但是每个条目里可能有多达 7 个回退的微操作,这使得 Apple M1 在使用不同的测试条件下能达到的大小可以是 623、853 甚至 2295 个。

在后端执行单元方面 Golden Cove 的变化相对较少,主要是浮点单元方面,首次在 x86 处理器上实现了两个快速浮点加法单元,相比之下 AMD 的 Zen 3 和 Intel 的 Willow Cove 都缺少快速加法器。
此外,我们前面提到过 Alder Lake 是支持 AV512 指令集的,但是需要关闭了 e-core 后才能开启 AVX-512,我们有理由相信 Intel 是经过深思熟虑后才决定把这个耗费了大量晶体管的单元给屏蔽掉的。

在整数流水线方面,Golden Cove 引入了新的端口(Port 10),使得 Golden Cove 一共有 5 个算法逻辑单元(ALU),这五个 ALU 都可以实现单周期执行 LEA(返回有效地址)指令,这样的设计让 Golden Cove 和 Zen 3 在整数后端方面达到接近的水平。

在内存子系统方面,Golden Cove 增加了一个 Load(加载)端口,合计可以每个周期跑 3 个 256 位 Load 操作(或者两个 512-bit Load 操作),以及可以跑两个 Store 操作。和 AMD Zen 3 是每个周期三个 Load 操作或者两个 Store 操作相比,Golden Cove 要强上一些。
在 Load/Store 的乱序执行潜力方面,Golden Cove 的 Load/Store 队列分别是 128 和 72(AMD Zen 3 从测试结果来看是 112 和 64,但是 AMD 方面表示实际的大小是 44 和 64,也许和内部的一些优化有关)。
上面就是 Intel 方面提供的 Gracemont 和 Golden Cove 微架构的资料,接下来,我们会进行一些底层测试,更进一步了解微架构的一些细节。
我们在这里使用的都是网上现成的底层测试软件,它们都有源代码提供,如果没特别提及的,大家也都可以循名称在网上搜索到。
为了便于对比和观察,如果不加说明,底层测试的频率都是锁定在 4GHz,关闭超线程,彻底禁止 Windows Defender,Windows 电源管理设置为性能模式,Linux 电源管理设置为 performance 模式。
MicrobenchX.IPC
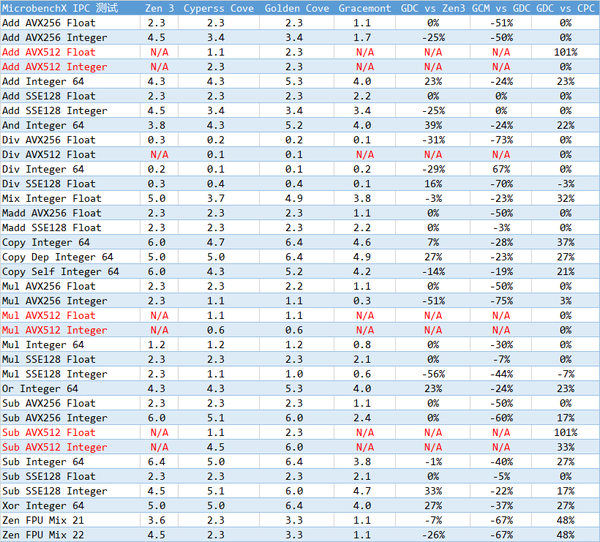
这是 MicrobenchX.IPC 1.03 版的测试结果,这里的 P-core 测试结果我加入了 AVX-512 的数据供大家参考。
测试结果分析:
1、Golden Cove 的第五个加法器提供了 23% 的提升;
2、和 Zen3 相比,Golden Cove 的 128-bit 向量整数加法、64-bit 整数除法、256-bit 向量整数乘法、128-bit 向量整数乘法存在一定的差距;
3、虽然 Gracemont 具备超多的执行单元端口,但是和 p-core Golden Cove 实际的底层 IPC 差距还是相当明显的。
4、从微架构角度来看,Golden Cove 属于 Tiger Lake 中 Willow Cove 的升级,但是它在桌面领域对应的前代产品则是采用 Cyperss Cove 微架构的 Rocket Lake。和 Cypess Cove 相比,Golden Cove 的 AVX512 浮点加法和减法性能快了一倍,整数+浮点混合指令快了 32%,不少指令都有相对显著的提升。
底层测试——流水线深度探测
流水线深度和处理器频率延伸能力、分支预测失败惩罚有密切关系,不过目前的处理器厂商一般都不公布相关的信息,这是有原因的。
现在的内核流水线设计异常复杂,不同指令流向经过的流水线工位数可能是不一样的。
为了探测 Golden Cove 的流水线深度,我使用了多种代码来测试。
下表中的左侧是以伪代码方式提供分支程序测试片段,以第 7 个测试(Test 6)为例:
Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
这段伪代码包含了一个 MOVZX 内存载入操作指令,根据处理器的不同,它可能需要额外的 5 到 6 个周期(可能更少)来执行,在支持乱序执行、乱序 L/S 的处理器中,这个动作占用的流水线工位通常会被掩盖掉。
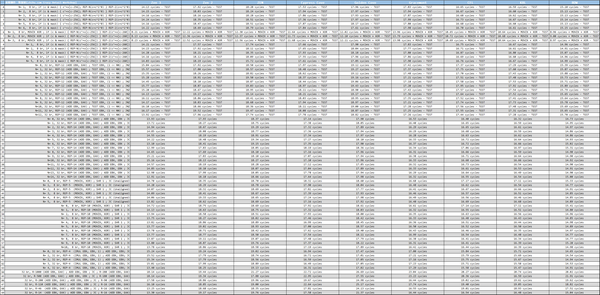
关于一些表格中的指令时延,例如 MOVZX,我们做了另行的测试。
在 Golden Cove 上录得的数据为 0.8 个周期,Zen3/Zen2/Zen+ 都是 1 个周期,Cypess Cove 是 0.9 个周期。XOR r64, r64 指令方面,Zen 3 是 0.2 周期,Zen2/Zen+/Zen1 是 0.3 周期。Test 指令方面,除了当年 Pentium 4 时代涉及访存的时候会有两周期时延外,这里测试的处理器都是 1 个周期时延。
从测试结果来看,在分支预测失败的情况下,Golden Cove 的惩罚周期大约是 13 到 26 个周期,其中最普遍的是在 18 周期左右,Gracemont 惩罚周期大约是 15 到 23 个周期,其中最普遍的是在 16 周期左右。据此我们估计 Golden Cove 的等效流水线深度大约是 18 级工位,而 Gracemont 是 16 级工位,由于 Golden Cove 具备可节省取值、解码阶段的微操作缓存,实际的流水线深度可能要接近 22 级甚至更深,Gracemont 由于采用了可以绕过预解码阶段的按需指令长度解码器设计,因此其实际流水线可能是 17 级。
取指、解码能力测试 处理器的流水线可以分为取指、解码、执行、写回四个工位,其中前端(front-end)是指取指和解码,执行和写回被称为后端(back-end)。
对于现在的超标量流水线处理器说,每个周期可以执行多条指令,前端需要为后端提供匹配的取指、解码能力,同时为了保证流水线闲置执行单元不浪费,人们还引入了分支预测单元,根据预测结果决定是否将下一条指令先派发给后端闲置的单元执行,待分支确定是否选中后再决定是否保留计算结果或者重置流水线。
op cache 也被称作 micro-op cache 或者 L0 I-Cache,它里面存放的是若干段处理器认为会被近期重复使用的微操作(micro-ops),所谓的微操作是 x86 处理器为了简化后端设计引入的处理器本机指令,是已经经过解码器解码的长度固定的本机指令。
在循环语句里的指令在很多情况下都是不断重复的,这些指令以微操作的方式放在 uop cache 后,后面重复执行这些操作的话,就无须经过解码器这个工位,直接发往后端的队列里等待发射执行。
uop cache 在 x86 上的原型是当年 Pentium 4 引入的 Trace Cache,Trache Cache 需要消耗大量的芯片面积,但是这是提高超长流水线架构处理器性能重要的一环。在 Pentium 4 终止后,Trace Cache 的瘦身版就以 uop cache 的形式引入。
要想了解处理器的能力,取指、解码是我们首先想要了解的,在这里我们使用 nop、sub、prefix cmp 8 等三种指令来做测试,其中 nop 指令是看空操作指令,x86 的 nop 长度是 1 个 字节,sub 是减法指令,和加法指令 add 一样在 x86 中指令长度都是两个字节,prefix cmp 是 8 字节或者说 64 位长的指令。
我们图表中给出的 prefix cmp 测试结果基于这样的指令:
[rep][addrovr]cmp eax, 0x7fffffff)
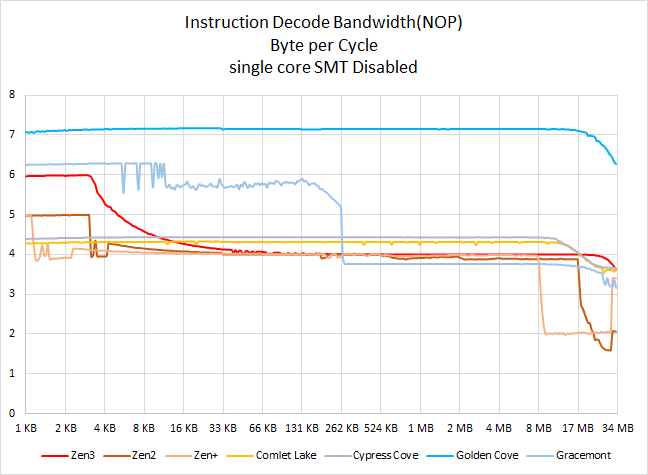
图表横坐标标注使用的是十进制数据格式,66KB 对应的是 64KiB,34 MB 对应的是 32 MiB,如此类推。大家要是有办法在 Excel 里实现二进制数据格式的话不妨告知一下。
Golden Cove 的测试结果实在有点让人感到惊艳。
首先,单字节的 NOP 指令看来是已经在很大程度上被 Intel “优化”了,解码带宽数据显示此时达到了每个周期 7 字节或者说 7 IPC,并且能一直维持到 L3 Cache 边界,我相信 Intel 对 NOP 这种什么都不干的指令做了一些特别的处理。
Gracemonmt 的 NOP 表现也是不错,其 6.x IPC 性能可以维持到 8KiB 的水平,并且在 128KiB 边界处也能维持到接近 6 IPC 的水平。
相较之下,去年曾经闪耀夺目的 Zen3 一下变得有点跟不上形势了。
我们使用的测试工具并非什么流行测试软件,Intel 应该不会投入资源特别优化,这个测试结果纯属因为微架构内部的一些新设计带来的。
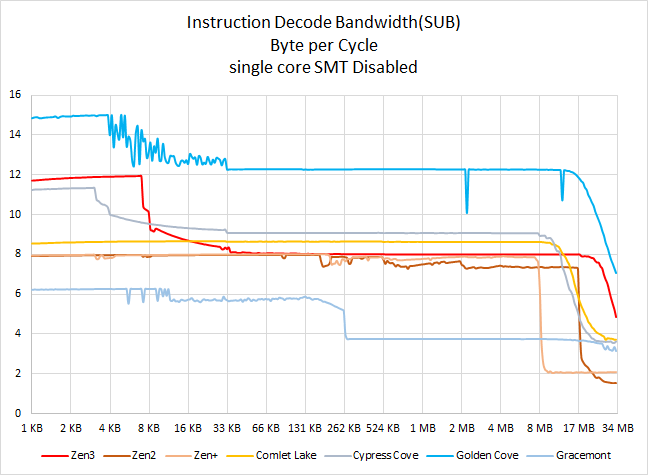
Golden Cove 的 sub 或者说减法指令解码带宽能在 4KB 边界处维持每周期 15 字节,sub 指令是双字节的,这意味着此时的解码性能至少有 7.5 IPC,这应该归功于 4K 条目大小的微操作缓存。
在接下来的更大区块里,Golden Cove 依然能维持 6IPC 的解码性能,其范围达到了 16 MiB,从程序员的角度,对于双字节指令 Golden Cove 在取指工位上具备比较真实的每周期 16 字节能力,这个能力可以维持到从 L3 Cache 取指。
Gracemont 在这里垫底了,在 8KiB 范围内只有 3 IPC 的水平,相当于 Golden Cove 的 1/5。
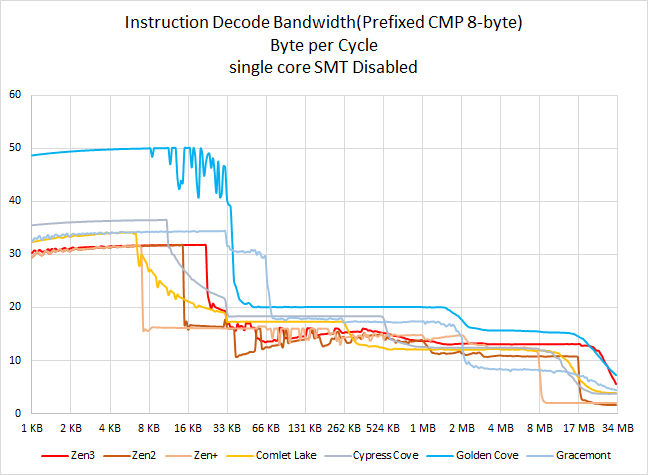
从测试结果来看,Golden Cove 对于更复杂指令(prefixed CMP-8)的解码能力是有显著提升的,可以在 32KiB 的范围内维持每周期 50 字节的解码带宽结果,相当于每个周期 6.25 IPC。
Gracemont 在这个测试中表现不逊色于 Zen3,能在 12KiB 范围内维持 4 IPC 的水平。
分支预测维持流水线充盈的重要性能手段,但是对于现在的长流水线处理器来说,分支预测失败的话对性能惩罚会非常高,因为这意味着运算结果要被抛弃并且流水线要被洗刷,即使是 1% 的命中缺失对性能来说也是非常致命的,当然这也意味着多增加 1% 的命中率收益会非常大。
现在的处理器在内部提供了性能计数器,可以让我们了解处理器运行某个程序消耗的周期数、指令数、分支指令数、分支命中失败指令数等数据,我这里在 Linux 下对 CPU2017 的 intrate 测试包进行了分支预测数据采集,结果如下。
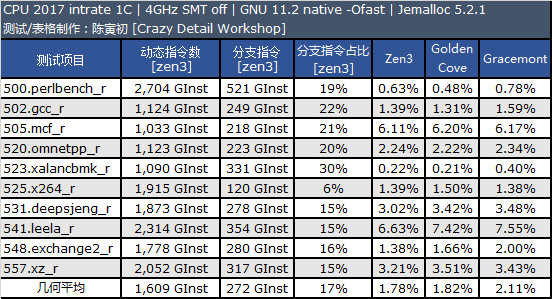
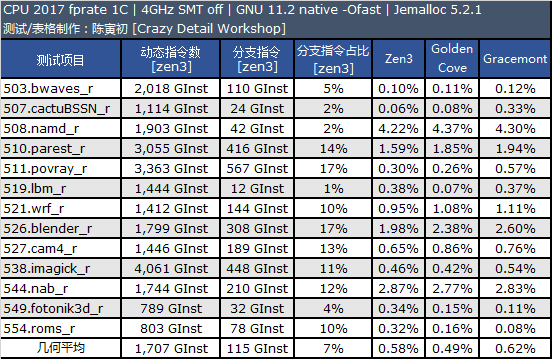
我们对 Alder Lake 的 Golden Cove 和 Gracemont 编译时使用的架构代号都是 Alder Lake,目前没有专门的 Golden Cove 和 Gracemont 架构开关。
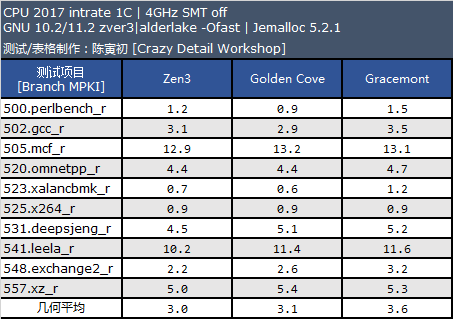
从测试记过来看,我认为 Golden Cove 的分支预测器在整数应用中的准确度是稍逊色于 Zen3 的,不过在浮点应用方面要好些,不过浮点应用的分支指令占比要低很多。
很多乱序执行处理器都采用了名为 Re-Order Buffer(重排序缓存)的技术,使指令在乱序执行后能够按照原来的顺序提交结果。指令在以乱序方式执行后,其结果会被存放在 ROB 中,然后会被写回到寄存器或者内存中,如果有其它指令马上需要该结果,ROB 可以直接向所需的数据。简而言之,ROB 的大小对于确保有足够的乱序驻留指令以及动态分支预测的恢复,对提升指令集并行度有不可忽视的作用,例如 Apple 的 M1 处理器在某些情况下可以做到等效 600 多个条目。
我这里使用 Travis Downs 的 rob size 工具来测试,测试的指令时单字节 NOP,单字节 NOP 的指令密度较高,可以减少微操作 cache 的影响。
测试结果如下:
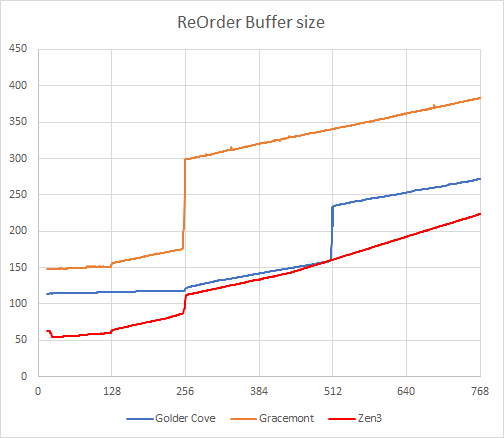
正如大家所看到的,我们的测试结果和 Intel 官方提供的信息一致,Golden Cove 和 Gracemont 的 ROB 大小分别是 512 和 256,Gracemont 不仅数量相差一倍,而且它表现出来的 NOP 指令测试耗时也要高出大约 29%。Zen3 的 ROB 是 256,但是它执行 NOP 指令的耗时要比 Golden Cove 更低,甚至在 ROB 溢出后依然比 Golden Cove 低,这可能和 Zen3 的微操作缓存有特别的压固优化有关。
接下来,让我们再看看指令窗口的物理寄存器堆(register file)大小。
从 Cyrix 在 95 年发布的 Cyrix M1 处理器是史上第一款具备寄存器重命名和乱序执行能力的 x86 处理器算起,x86 处理器的乱序执行至今已经有 25 年了。
在绝大部分情况下,寄存器重命名不一定和乱序执行是挂钩,例如 Intel IA64 就有多达 128 个通用整数寄存器,虽然也涉及寄存器重命名的概念,但这是编译时的事情,在编译时做寄存器重命名也不见得都是好事(容易导致代码膨胀,降低指令高速缓存命中率)。
对于 x86-64 这种只有 16 个指令集架构寄存器的指令集架构而言,寄存器重命名是保障乱序执行必不可少的技术,要重命名,自然得需要有足够的物理寄存器才行,物理寄存器越多,可供重命名的资源也就越多,维持乱序执行的能力就越强。
我们使用 robsize 同样的测试程序进行了物理寄存器堆(PRF)大小的探测。这里说明一下,我们前面的 rob 大小探测使用的是 nop (空操作)指令,不占用任何寄存器,而接下来做的 PRF 大小推测测试,使用的是一连串的寄存器 add(加法)指令。
需要注意的是,物理寄存器堆里同时含有乱序执行中可用于推测执行的推测寄存器数量和已提交寄存器数量,因此这种测试方式不能把直观地把整个物理寄存器堆的大小给出来,它只能测量出可用于推测执行的寄存器数量。
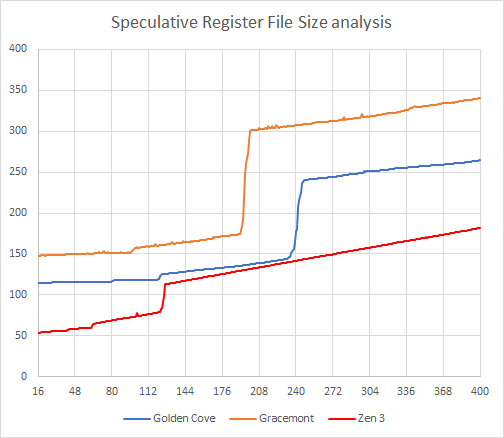
从测试结果来看,Golden Cove 可用于推测执行的寄存器堆大小和 Rocket Lake/Cypress Cove 没有什么大的区别,都是 240 个。Gracemont 要小一些,也有 192 个,但是已经大于 Comlet Lake(第十代酷睿或者说 Skylake)的 144 个,Zen3 采用分离式整数/浮点调度器设计,它的推测可用寄存器堆大小大约是 128 个。
接下来我们看看 SIMD 向量物理寄存器堆的大小,这里使用的是 AVX 中的 XOR 指令,在 x86 指令集中 AVX 的寄存器名称一般都是使用 ymm 表示。
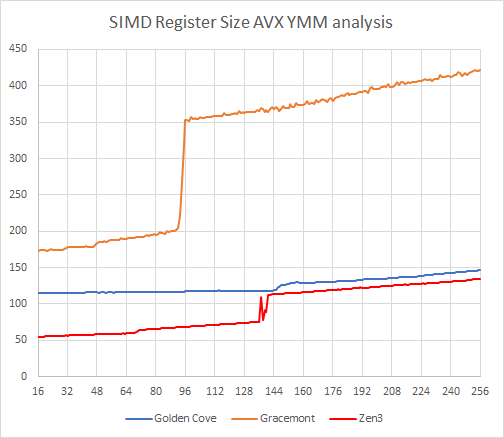
Gracemont 的 AVX ymm 寄存器队堆大小只有 96 个,Golden Cove 和 Zen3 都是 144 个,当寄存器堆大小溢出的时候,Golden Cove 的性能衰减程度较低,而 Gracemont 出现了非常显著的指令吞吐衰减,以 Gracemont 数量众多的执行端口,寄存器堆不够用时的压力相对明显些。
现在的处理器不仅可以乱序执行指令,还能乱序加载(Load)、存储(Store)数据,这就涉及到 Load/Store Buffer。
x86 属于 CISC 指令集,它的指令里可以同时有访存、寄存器、立即数等操作,在 SPEC CPU 2017 中,SPEC CINT2017 和 SPEC CFP2017 的 LD/ST 指令占比就分别高达34% 和 39%,Load/Store Buffer 对 x86 的性能影响也是不容小觑的。
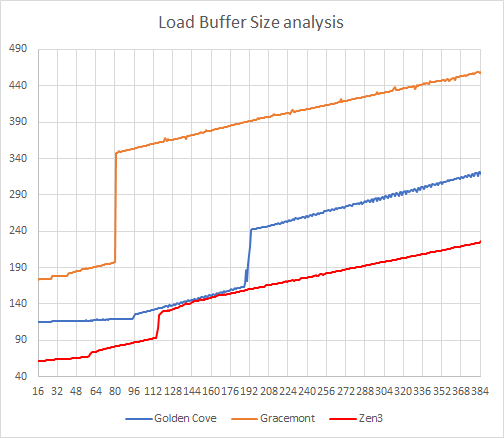
从测试结果来看,Gracemont 的 Load 缓存大小是 80 到 82 个条目,这点是非常清晰的。
Golden Cove 的大小应该是 192 条目左右,作为对比,Golden Cove 的台式酷睿上一代 Cypress Cove 是 128,Golden Cove 增加了 50%。
AMD 官方的说法里 Zen3 的 Load buffer 只有 44(外加 28 个地址生成器缓存,合计 72)个,但是根据软件的测试结果,我觉得从软件角度或者程序员角度,其大小更像是 114-118 条目之间(之前我说过是 116)。
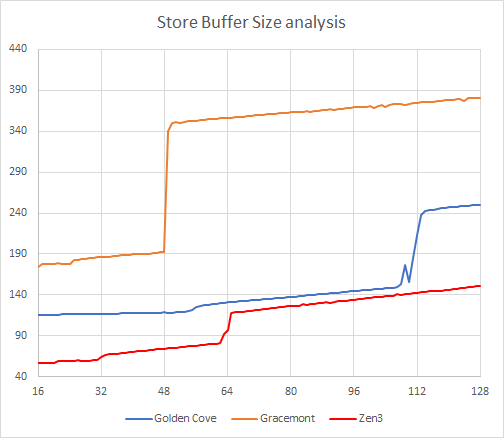
从测试结果来看,Golen Cove 的 Store Buffer 大小大约是 112 个条目,Gracemont 是 48 个,Zen 3 是 64 个。
翻查之前的测试数据,Golden Cove 的上一代(Cypress Cove)是 72 个条目,这意味着 Golden Cove 在这方面的大小增加了 56%,实现乱序 Store 的概率会有一定的增强。
需说明的是,乱序 L/S 的效果与其他乱序执行指令一样取决于多方面的因素,缓存或者说队列大小只是其中一个较为重要的影响因素。
CPU 2017 是非盈利机构 SPEC(标准性能评估公司)推出的 CPU 性能评估套件,SPEC 成立于 1998 年,会员包括 Intel、AMD、IBM、DELL、联想、华硕、技嘉等业界大公司,每隔大约 10 年就会推出一版新的 CPU 性能评估套件,CPU 2017 是该机构在 2017 年推出的,是所有处理器、电脑厂商做处理器性能评估的最重要手段之一(如果不是使用上有一定门槛,上面这句话的“之一”是可以省略的)。
SPEC CPU 的特点是由各个机构提供实际应用的源码,它的每一个子项目其实都是源自真实应用修改而来,其修改主要是针对可移植性和遵循的语言标准,例如 x264 的真实版本采用了大量的汇编代码,但是这样的形式不利于移植到不同指令集架构上测试,因此 CPU 2017 中的 x264 采用的是纯 C 语言版本。
和上一版本 CPU 2006 相比,CPU 2017 的代码已经全面更新,虽然依然使用 C/C++ 和 Fortran,但是相对以前的版本来说,已经变成了多语言的大混装。Fortran 语言同时出现在浮点和整数测试集,而非像以往那样只出现在浮点测试集。
CPU 2017 的规则更加严谨,speed 测试集允许使用 OpenMP 多线程处理,主要测试较大数据集和较大访存压力下的单任务多线程性能,而 rate 测试集则只允许单线程,禁止自动并行化,但是允许以多任务的方式跑多个 rate 测试,目的是测试吞吐率,单个 rate 任务的访存压力要比 speed 小很多。
不过 speed 测试集也不是全部项目都支持多线程,只有浮点密集型的 fpspeed 所有项目支持多线程,整数密集型的 intspeed 10 个子项目中只有最后的 657.xz_s(数据压缩)是支持多线程的。
这样的规则让以往 CPU 2006 以及更早版本中常见的编译器自动并行化“优化”手段被禁止使用,减少了测试结果的混乱(测试如果使用了编译器自动并行化后,实际上变成了编译器比拼),提高了可比性。
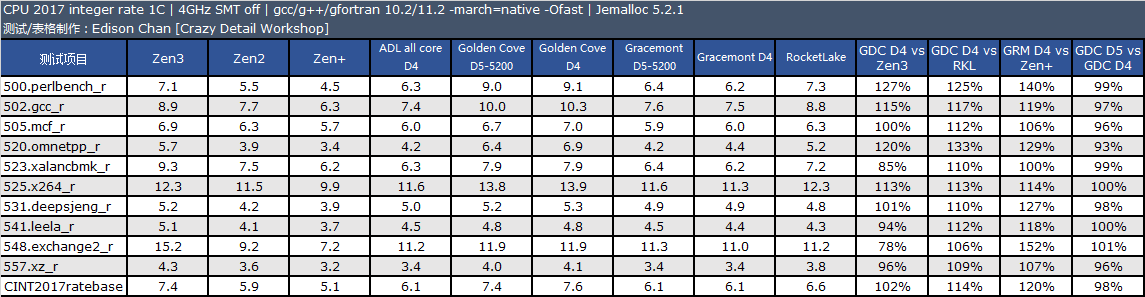
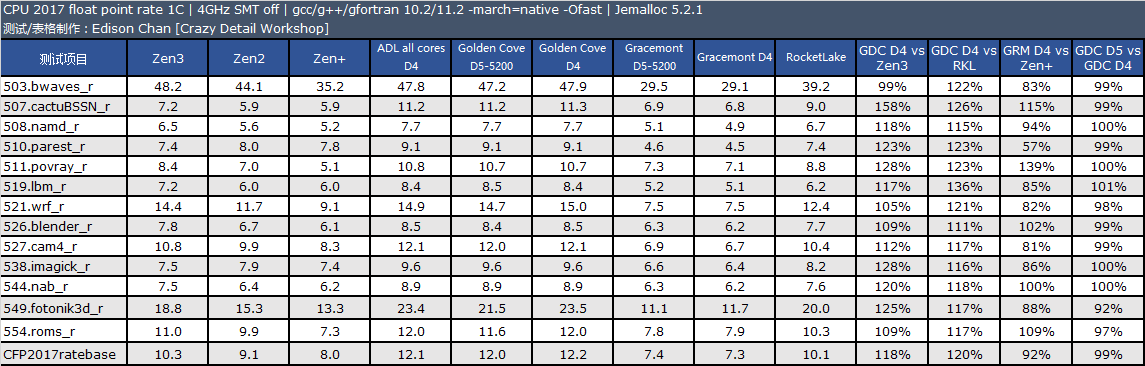
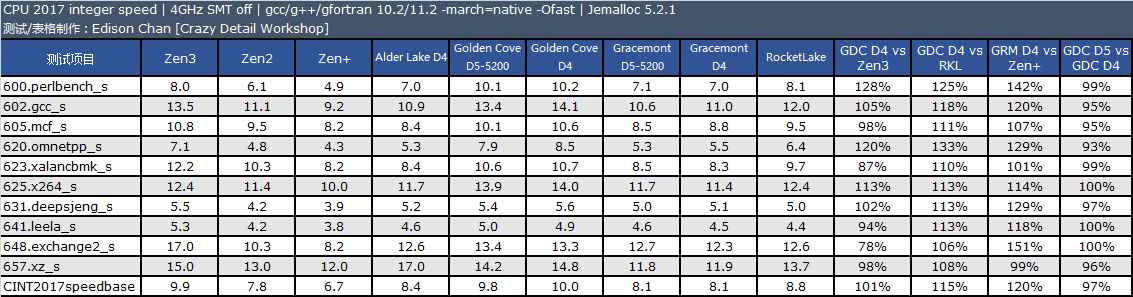
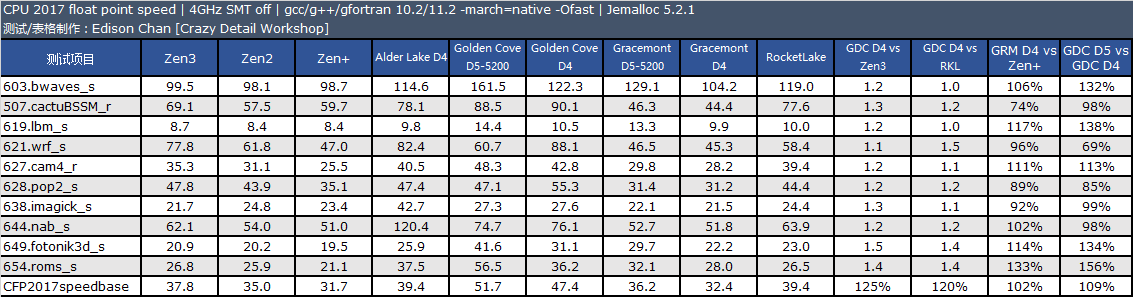
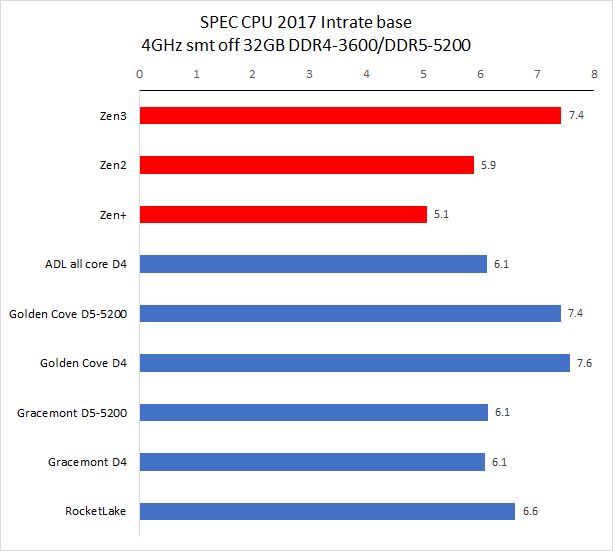
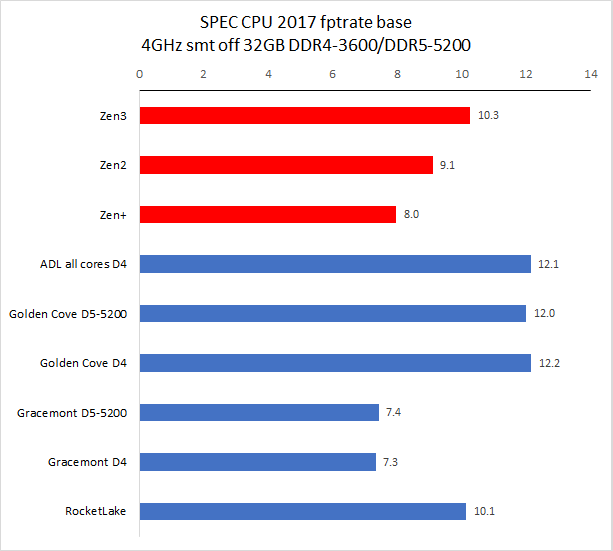
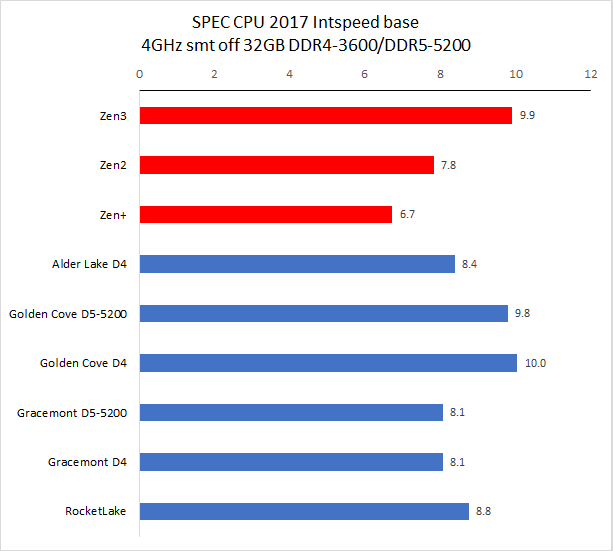
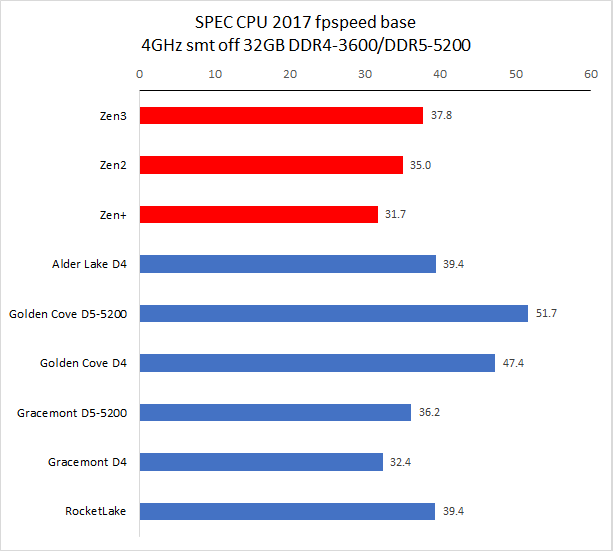
备注:CPU 2017 测试需时,目前我们的旧数据只有 Zen3 4GHz 使用了 11.2 版编译器,11.2 版编译器在整数单线程、多线程和浮点多线程中有一点性能改善。其余旧处理器运行的均为 10.2 版编译器编译出来的代码。
从测试结果来看,单线程性能方面,Golden Cove 的整数性能是 Zen3 快大约 2%,比 Rocket Lake 快大约 14%,浮点方面优势会大一些,分别是 18% 和 20%。
在多线程项目中,Golden Cove 的整数性能是 Zen3 快大约 1%,比 Rocket Lake 快大约 15%,浮点方面优势会大一些,分别是 25% 和 20%。
Gracemont 的性能和 Zen+ 非常接近,单线程整数/浮点性能分别是 Zen+ 的 120% 和 92%,多线程整数/浮点分别 120% 和 102%。
大家可能注意到了,我们这里单独列出了全核、单纯 Golden Cove、单纯 Gracemont 的数据,这么多的测试对我们来说是非常耗时的,但是从结果来看也许是有一定意义的。
我们使用的 Linux 发行版是 Ubuntu 21.10,手动安装了 Kernel 5.15,按照理想的情况,Intel Thread Director 如果能正常运作,应该可以把重载的线程都扔到 p-core 或者说 Golden Cove 上运行,理论上单线程性能时全核和指定 Golden Cove 的数据应该是一致的。
然而事实并非如此,至少我们目前遇到的情况是 Thread Director 把几乎所有的线程都优先扔到 e-core 或者说 Gracemont 上,这使得全核的数据比较一般,基本就是 Gracemont 的数据(截图使用的是默频时候的状态):
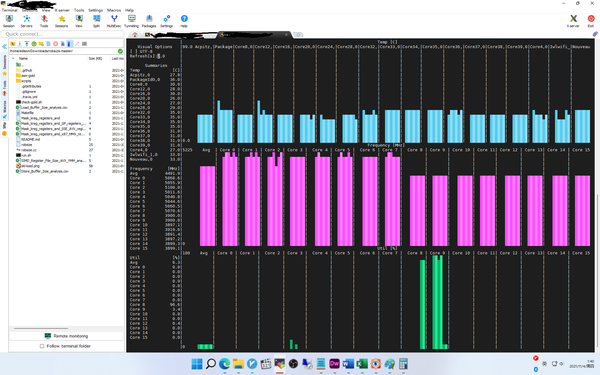
fpspeed 的结果会好些,因为此时 16 个内核都在运作。然而,当我查看内核调用情况的时候,情况却是这样的:
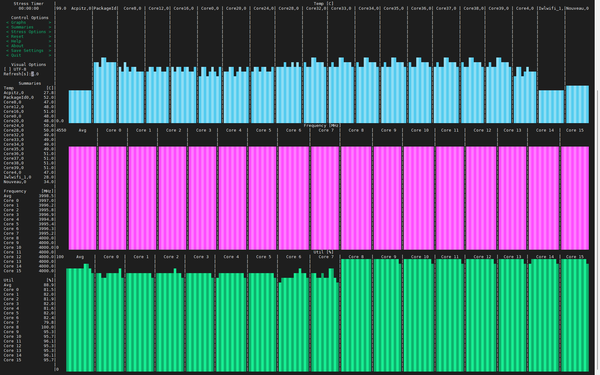
此时虽然是 16 个内核都在运作,但是 P-core 的占用率只用了 90% 左右,而 e-core 则是满载运行。当然,这个问题发生在Ubuntu下,而在Windows 11下就没问题。
接下来让我们看看默频的测试结果,虽然说是默频,但是我们已经在 Linux 中启用了 performance 高性能模式,避免省电模式下那种频率大幅波动造成性能损失的情况。
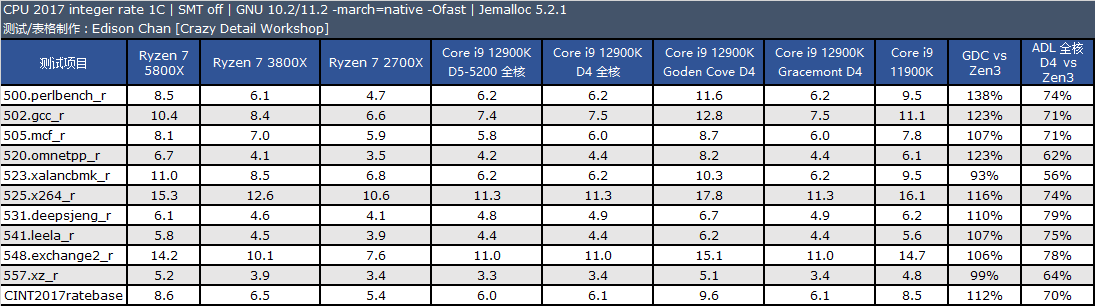
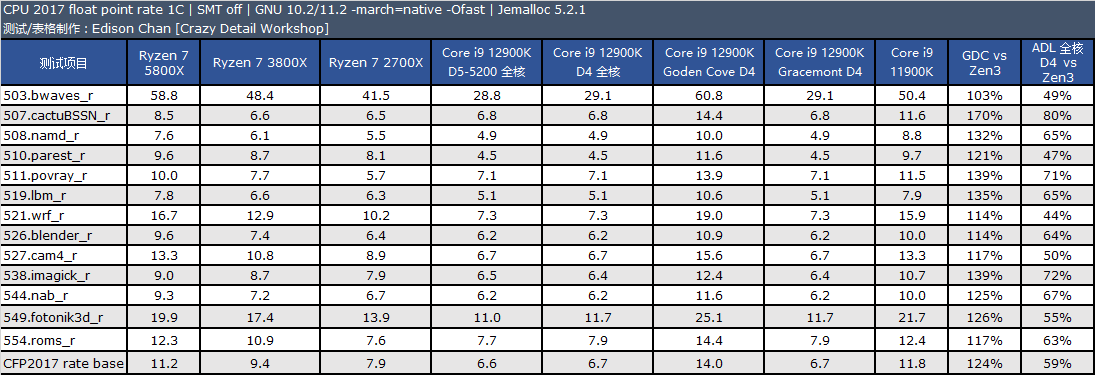
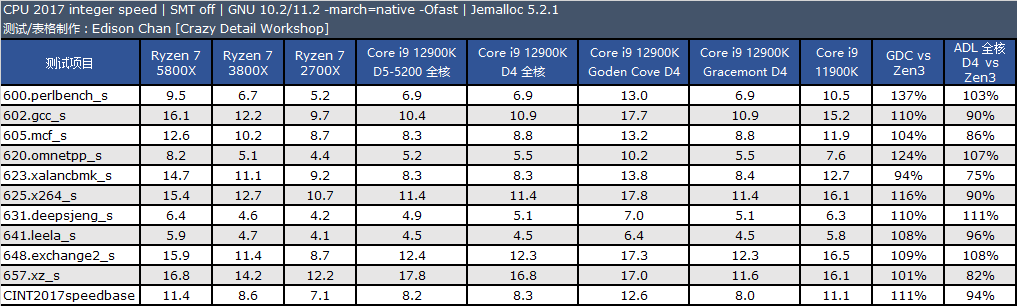
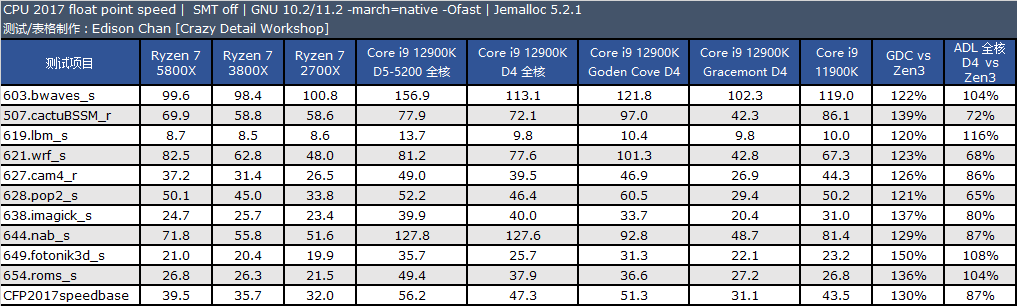
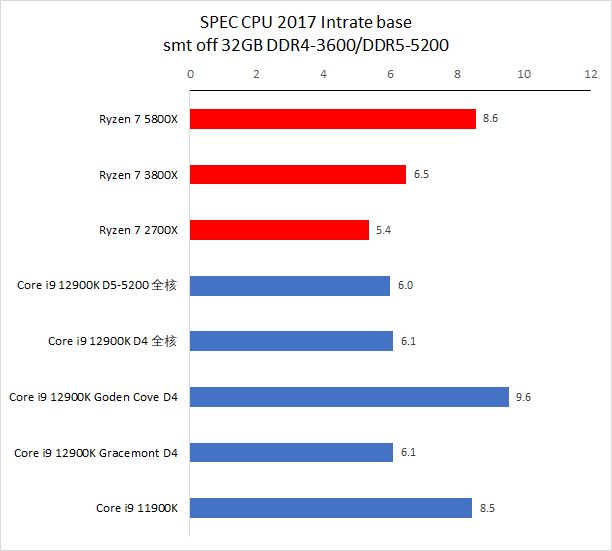
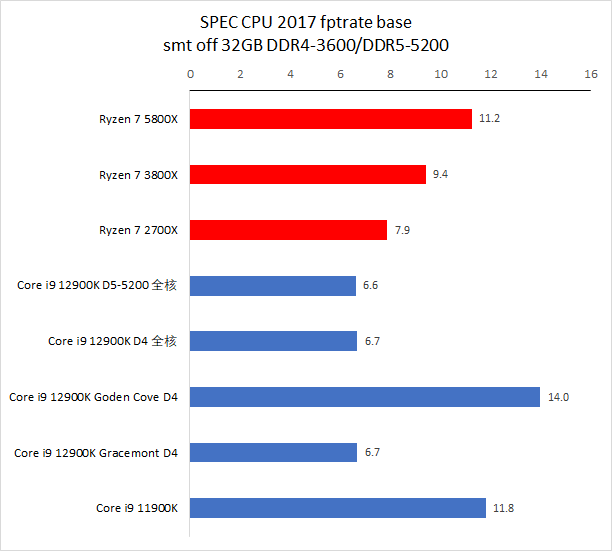
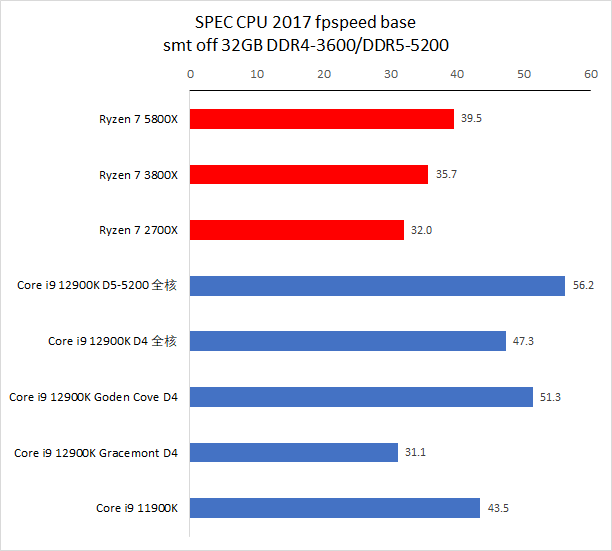
备注:CPU 2017 测试需时,目前我们的默频旧数据 10.2 版编译器编译出来的代码,而 ADL 使用的编译器为最新的 11.2,11.2 版编译器会比 10.2 有一点性能提升效果,总体大约在 1% 到 3%。
在默频下,12900K 的 P-core 的单线程整数和浮点性能分别是 5800X 的 1.12 倍和 1.24 倍,在 intspeed 和 fpspeed 下分别是 1.11 倍和 1.30 倍。
默频下由于调度器支持并未完善造成的磨洋工情况比 4GHz 更甚:
多线程测试的时候 P-core 只有 60% 不到的占用。
从微架构角度来看,Alder Lake 中的 Golden Cove 在指令解码、执行能力上较以往的 x86 处理器都有提高,特别是指令解码能力方面我认为达到了大幅度提升。在同频下,作为 E-core 的 Gracemont 的整数和浮点性能达到了 Golden Cove 的 80% 和 60%,默频时分别为 63% 和 48%。
当然,变化如此之大的架构也需要工艺来支撑,要知道ice lake其实已经设计出来多年,只不过一直没有工艺开实现落地而已,后来的10nm也只能勉强上到笔记本,而桌面版就直接流产。从skylake 6700K一直到Rocket Lake 11900K,14nm已经6个年头。而现在Alder Lake 12代处理器终于可以跟祖传的14nm说拜拜了,全新的intel 7节点工艺来了。

ADL工艺为intel 7,这个7并不是值的是物理上的7nm,本质只是10nm superFin的增强版本,intel 7更多只是营销上的话术。intel 7相比之前的10nm SuperFin,主要是优化了FinFET晶体管,单瓦性能有10-15%的提高。Intel 7 性能是通过更高应变的晶体管、更好的能量控制以及改进的功率传输和金属堆栈来实现的。
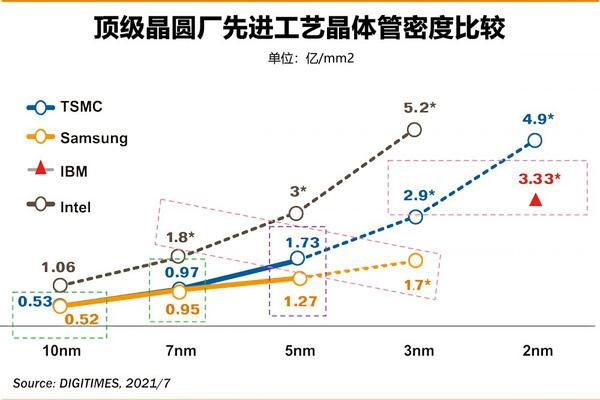
台积电和三星的号称nm数实际上早和栅格宽度脱节,完全是不讲武德,因此intel再老老实实的依据Gate宽度标注就是老实人吃闷亏。实际上intel 10nm的晶体管密度是每mm2 106万,比台积电7nm的97万还要高,再加上15%的性能提升幅度,因此现在把10nm superFin增强叫intel 7也并不为过。
Intel的14nm从2015年5代一直用到2021年的11代,可以说是祖传手艺也不为过。我在之前就说过,虽然现在intel 10nm工艺产能已经过半,但intel迟迟不愿升级桌面处理器的工艺主要有两方面的原因。
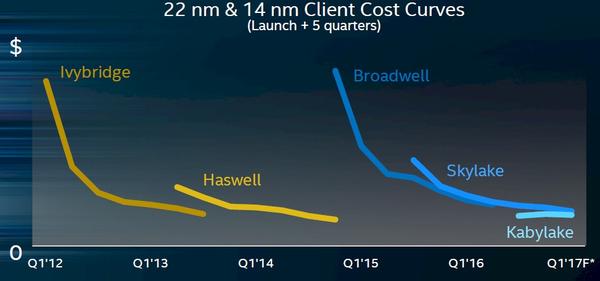
第一个原因就是成本,处理器切换新工艺,虽然新工艺有更高的晶体管密度,单个晶圆可以切割出来更多的芯片,这样可以降低成本,但新工艺需要数以十亿甚至百亿美元级别的投资,所以在工艺升级的节点,处理器的成本是大幅上升的,远远大于架构变化而工艺不变的情况成本。所以intel在竞争压力不大的情况下,将14nm+skylake从6代一直用到10代,这样延长工艺的生产周期的后期,设备投入摊薄基本就可以忽略不计。但在真正威胁Zen 3出现的时候,RKL硬上14nm就有些过于勉强了。 第二个原因就是晶体管性能,工艺升级,一般都可以大幅提升晶体管密度,再就是降低功耗,但晶体管性能却不一定是提升的,特别是在工艺线宽的初期更是经常如此。以台积电的7nm工艺为例,首批主要是针对功耗优化的LP工艺,LP用在手机SoC上问题不大,但用在Zen 2和RX5000系列显卡上频率就上不去,台积电的7nm要等到老黄为做A100带着台积电重新走了一次HP才基本堪用,后来的Zen 3和RX 6000的频率就高很多,特别是显卡,甚至可以跑到2.7GHz以上。
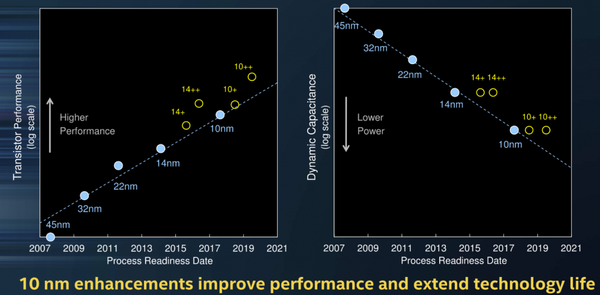
Intel 10nm也是类似情况,第一代ice Lake虽然密度功耗不错,但频率上不去,第二代的Tiger Lake 10nm superFin虽然有所提升,但性能还是赶不上14++,直到ADL的10nm SuperFin增强,就是现在的intel 7,绝对晶体管性能才彻底抛离14++。桌面处理器需要高频来达成更高的性能,只有在intel 7之后才能达成高频,这就是为什么直到ADL才上新工艺的第二个原因。

youtube大佬DERBAUER对12900K开盖,核心面积仅为208mm2,十分接近10900K 206mm2的水平。
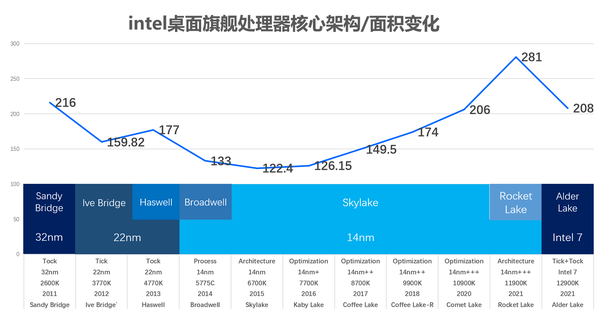
之前RKL的核心规模过大,使用14nm面积高达281mm2,其实这样的规模对于普通桌面处理器都过于勉强,而现在ADL的208mm2又再次回到正轨。之前经典的tick-tock策略是架构工艺交替更新,但之前的14nm修修补补挨过了6年7代,而这次ADL不仅是工艺大升级到intel 7,架构方面也发生了天翻地覆的变化,可以说是tick+tock同时兑现,这样大的变革是前所未有的。
 4
4 0
0
 0
0 4
4


